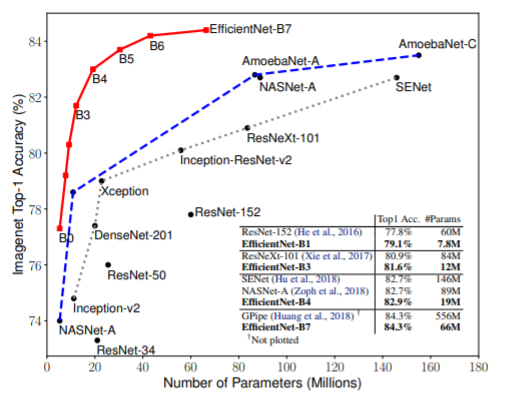
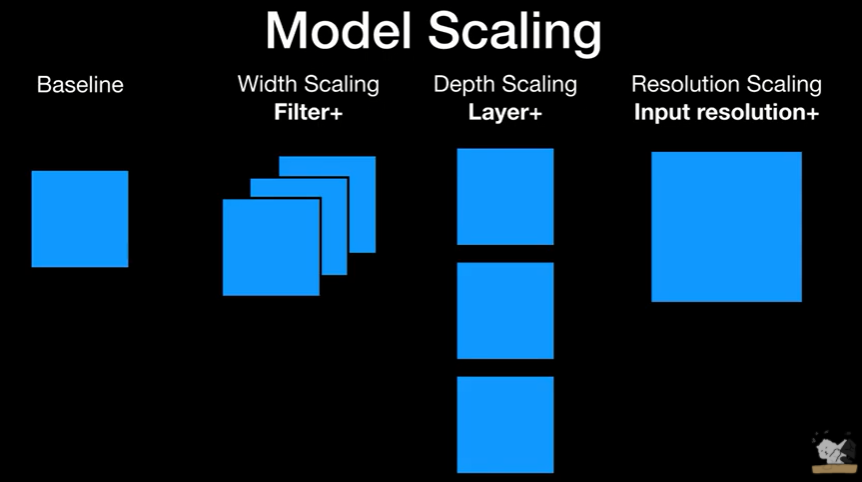
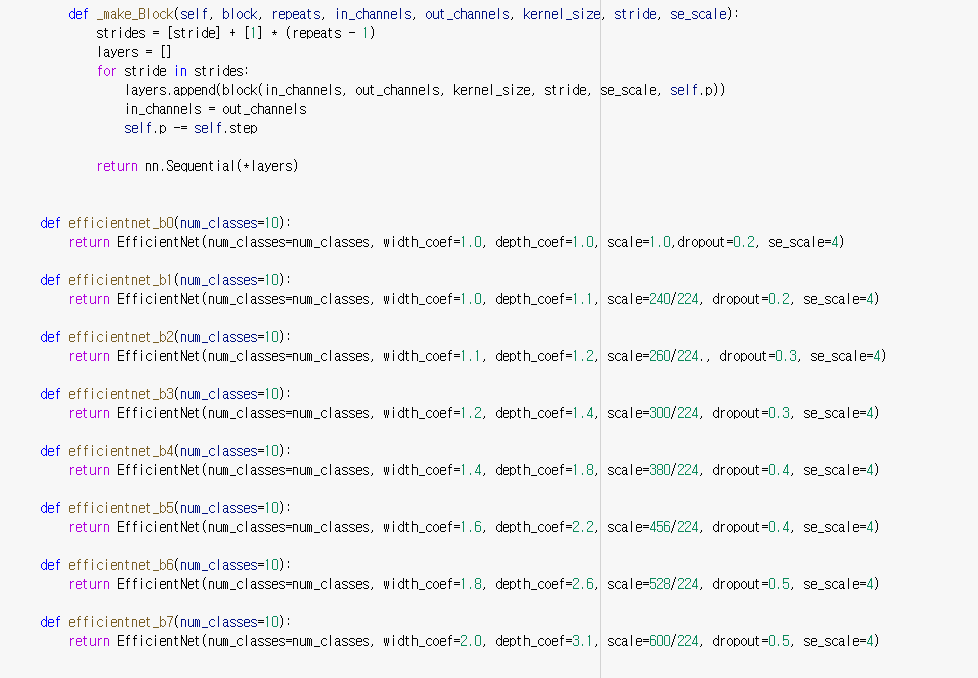
Dataset
from glob import glob
from torch.utils.data import Dataset, DataLoader
from PIL import Image
import torchvision.transforms as T
class my_dataset(Dataset):
def __init__(self, image_path, classes, transform=None):
self.image_path = image_path
self.labels = self.get_labels(image_path, classes)
self.transform = transform
self.classes = classes
def get_labels(self, image_path, classes):
label_list = []
for path in image_path:
temp = path.split('/')[-1]
temp = temp.split('\\')[-2]
num = classes.index(temp)
label_list.append(num)
return label_list
def __len__(self):
return len(self.image_path)
def __getitem__(self, idx):
img = Image.open(self.image_path[idx])
if self.transform is None:
return img, self.labels[idx]
else:
return self.transform(img), self.labels[idx]
train_data_path = glob('./data/CIFAR-10-images-master/train/*/*.jpg')
test_data_path = glob('./data/CIFAR-10-images-master/test/*/*.jpg')
my_mean = [0.485, 0.456, 0.406]
my_std = [0.229, 0.224, 0.225]
my_transforms = T.Compose([
T.Resize((100, 100)),
T.Normalize(mean=my_mean, std=my_std)
])
train_loader = DataLoader(custom_dataset(train_data_path, classes, my_transforms),
batch_size=10,
shuffle=True,
drop_last=True)
test_loader = DataLoader(custom_dataset(test_data_path, classes, my_transforms),
batch_size=10,
shuffle=True,
drop_last=True)
Transforms
normalize_transform = T.Normalize(
mean=[0.485, 0.456, 0.406], std=[0.229, 0.224, 0.225])
if is_train:
transform = T.Compose([
T.Resize(config.image_size),
T.RandomHorizontalFlip(p=config.prob),
T.Pad(config.padding),
T.RandomCrop(config.image_size),
T.ToTensor(),
normalize_transform,
RandomErasing(probability=config.re_prob,
mean=[0.485, 0.456, 0.406])
])
transforms에 속한 클래스
1. transforms.CentrCrop(size)
- 주어진 PIL 이미지의 중앙을 기준으로 size X size 크기로 자른다.
2. transforms.Grayscale(num_out_channels=1)
- 주어진 이미지를 그레이스케일로 변형한다.
- parameter에 1or3을 지정할 수 있는데 1이면 싱글채널이 반환이 되고, 3이면 r==g==b인 3채널이 반환이 된다.
3. transforms.Pad(padding, fill=0, padding_mode='constant')
- 이미지에 대해 컨볼루션을 거칠 때 이미지의 크기와 컨볼루션 커널의 크기가 맞지 않아 이미지의 사이드를 어떠한 수 로 채울 때 사용한다.
- padding : int, tuple 형식으로 지정할 수 있다. 만약에 int형으로 한 개의 수를 입력한다면 이미지의 모든 사이드를 그 수로 채운다는 것이다. 그리고 튜플형식으로 (a,b)를 입력한다면 왼쪽과 오른쪽은 a로 위와 아래는 b로 채운 다는 것이다. 마지막으로 (a,b,c,d)를 입력한다면 왼쪽, 위, 오른쪽, 아래를 각각 a,b,c,d로 채우게 된다.
- fill=0 : padding을 하기 위한 값을 입력한다. default는 0이며, R, G, B 색 공간일 때는 튜플형식으로 입력을 한다.
- padding_mode='constant' : padding_mode를 설정하게 되는데 default는 constant이다.
4. transforms.Resize(size, interpolation=2)
- 주어진 PIL 이미지를 입력한 size로 크기조정을 한다.
- size : 만약에 sequence 형식으로 (h,w)로 입력을 한다면 h,w로 크기가 조정이되며, int형식으로 한 개의 수가 입력이 된다면 h, w중 작은 것이 입력된 수로 조정이 된다. 예를 들어, h>w라면 (size*h/w, size) 이렇게 크기가 재조정이 된다.
5. transforms.Normalize(mean, std, inplace=False)
- 주어진 이미지를 mean, std의 값을 통해 정규화를 한다.
- mean : (sequence)형식으로 평균을 입력하며, 괄호 안에 들어가 있는 수의 개수가 채널의 수이다.
- std : (sequence)형식으로 표준을 입력하며, 마찬가지로 괄호 안에 들어가 있는 수의 개수가 채널의 수이다.
- inplace(bool, optional) : x
6. transforms.ToTensor()
- PIL 이미지 또는 numpy.ndarray 형식의 이미지를 tensor 형식으로 변환한다.
- 0~255의 범위를 갖는 (H x W x C)의 형식을 0.0~1.0의 범위를 갖는 (C x H x W)의 형식으로 변환한다.