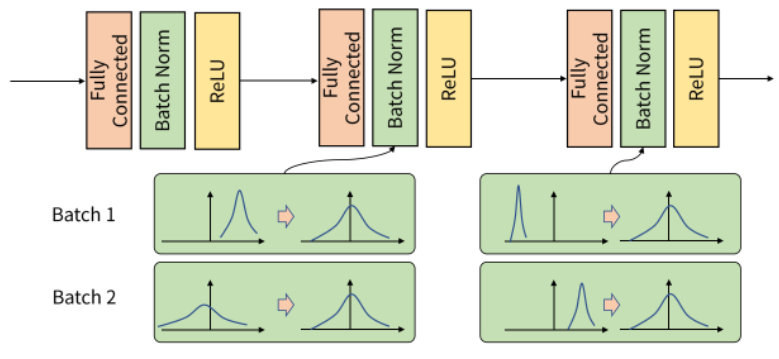
위의 사진과 같이 input 데이터가 각 층을 지나면서 연산 전/후에 데이터 간 분포가 달라질 수 있습니다.
Batch 단위로 학습을 하게 되면Batch 단위간에 데이터 분포의 차이가 발생할 수 있습니다.
예를 들어, 고양이와 강아지를 분류하는 모델을 학습시킬 때 학습 데이터로 고양이 이미지를 '러시안 블루'종만 사용하고 테스트 데이터로 '페르시안' 종의 고양이를 분류하려고 한다면 학습 데이터의 분포와 테스트 데이터의 분포가 다르기 때문에 학습시킨 모델의 분류성능은 떨어질 것이며 이처럼 학습 데이터와 테스트 데이터의 분포가 다른 것을 covariate shift라고 부릅니다.
즉, Covariate shift는 공변량 변화라고 부르며 입력 데이터의 분포가 학습할 때와 테스트할 때 다르게 나타나는 현상을 말한다.
Batch Normalization
Batch Normalization
Internal Covariant Shift 현상을 방지해주기 위해서 Batch Normalization을 사용합니다.
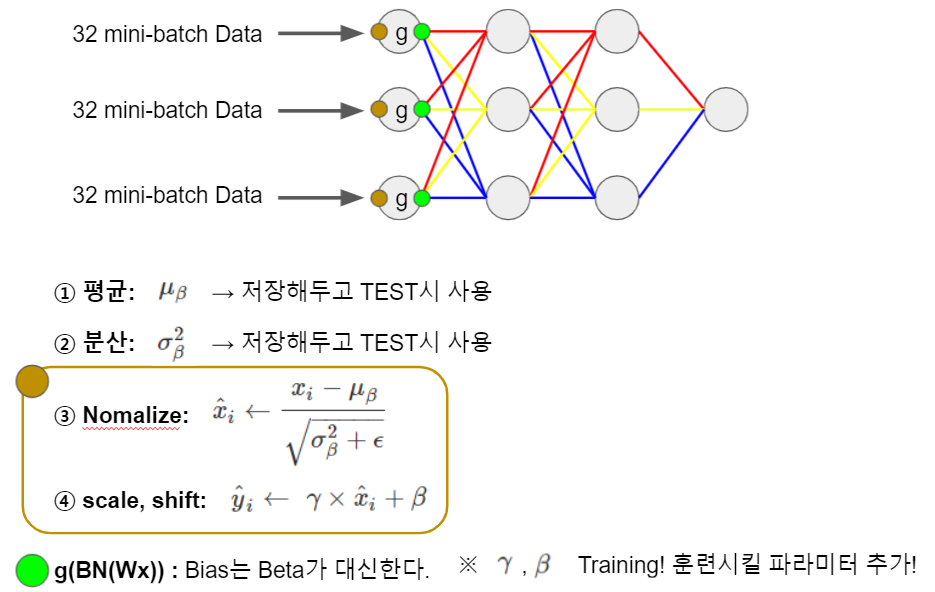
Batch Normalization은 각 배치 데이터의 평균과 표준편차를 이용하여 평균은 0, 표준 편차는 1로 데이터의 분포를 조정해줍니다.
Batch Normalization 순서
위 사진은 한경훈 교수님의 유튜브에서 가져왔습니다.
여기서 주목해야 할것이 γ와 β 입니다.
Batch Normalization의 식입니다.
이 식을 살펴보면, (평균: 0, 표준편차: 1) → (평균: β, 표준편차: γ) 로 바꿔주는 식입니다.
이 두 변수는 저희가 지정해주는 것이 아니라 학습을 진행하며 업데이트가 되는 가중치라고 볼 수 있습니다.
γ와 β를 사용하는 이유
γ와 β : X
평균 0, 표준편자가 1인 데이터들은 위의 사진과 같이 가운데에 몰려 있을 것입니다.
그렇다면 거의 linear하기 때문에 non linear 할 수 없습니다.
γ와 β : O
그렇기 때문에 γ와β를 사용하여 non linear한 부분에 위치할 수 있도록 재배치를 해주는 것입니다.
그 모델에 더욱 적절한 위치를 위해서 train parameter 로 두는것입니다.
위와 같이 재배치를 이룸으로써 Gradient Vanishing 현상도 완화시켜 줄 수 있게 됩니다.
진행 순서 입니다.
TEST 시에는 어떻게 사용할까
Train을 하면서 구한 평균과 분산에서 각각의 sample 평균을 사용합니다.
예를 들어 3200개의 데이터를 학습하고 32의 배치를 가지고 학습을 진행한다고 가정하면
처음 Train의 32개의 데이터에 대한 평균과 분산은 Train이 덜된 weight와 bias에 의해 쓰레기값이라고 봐도 무방한 값들이 나올 수 있습니다.
그래서 exponential moving average를 이용하여 초기에 학습된 데이터들에 대한 평균과 분산에 대해서는 가중치를 적게주어 영향을 적게 받을 수 있도록 하고 후반부에 학습된 데이터들에 대한 평균과 분산에 대해서는 가중치를 크게 주어 사용합니다.
import numpy as np
import matplotlib.pyplot as plt
from math import *
def sigmoid(x):
return 1 / (1 + np.exp(-x))
def ReLU(x):
return np.maximum(0, x)
if __name__ == '__main__':
x = np.random.randn(1000, 100) # 데이터
node_num = 100 # 각 은닉층의 노드(뉴런) 수
hidden_layer_size = 5 # 은닉층 5개
activations = {} # 활성화 결과 저장
for i in range(hidden_layer_size):
if i != 0:
x = activations[i-1]
# w = np.random.randn(node_num, node_num) * 1 # 표준편차 1
# w = np.random.randn(node_num, node_num) * 0.01 # 표준편차 0.01
# w = np.random.randn(node_num, node_num) * sqrt(1.0 / (node_num + node_num)) # Xavier
w = np.random.randn(node_num, node_num) * sqrt(2.0 / node_num) # He
a = np.dot(x, w)
z = sigmoid(a)
# z = ReLU(a)
activations[i] = z
# 히스토그램 그리기
for i, a in activations.items():
plt.subplot(1, len(activations), i+1)
plt.title(str(i+1) + "-layer")
plt.xlim(0.1, 1)
plt.ylim(0, 7000)
if i != 0:
ax = plt.gca()
ax.axes.yaxis.set_ticks([])
plt.hist(a.flatten(), 30, range=(0, 1))
plt.show()
#include <chrono>
using namespace chrono;
// 시간 start
uint64_t start_microsec = duration_cast<microseconds>(system_clock::now().time_since_epoch()).count();
// 시간 end
uint64_t end_microsec = duration_cast<microseconds>(system_clock::now().time_since_epoch()).count();
// 걸린 시간
uint64_t dur = end_microsec - start_microsec;
duration_cast<원하는 시간 단위>(system_clock::now().time_since_epoch()).count();