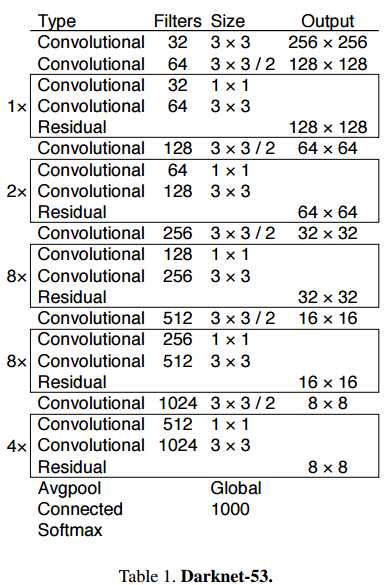
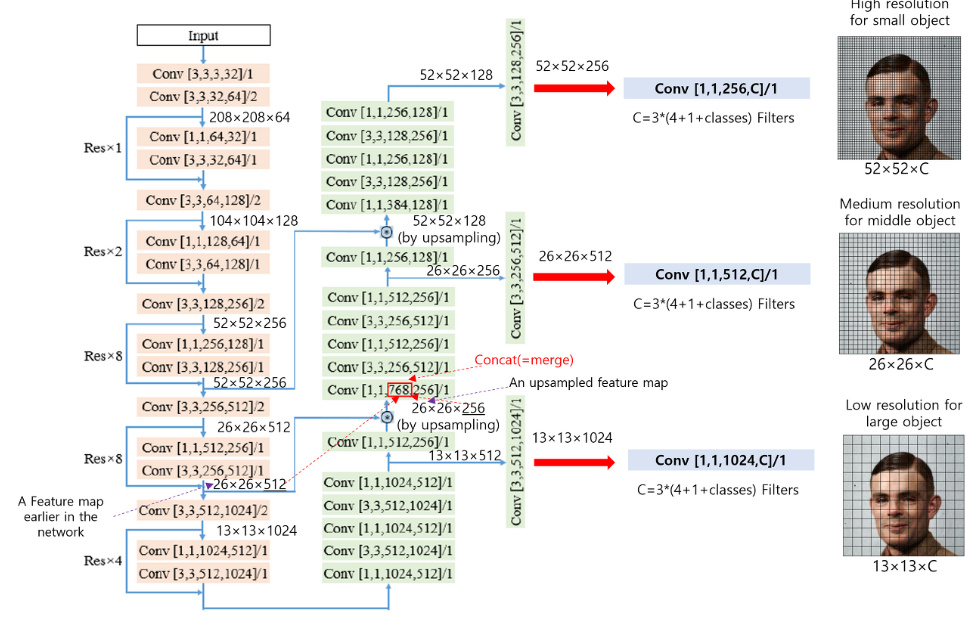
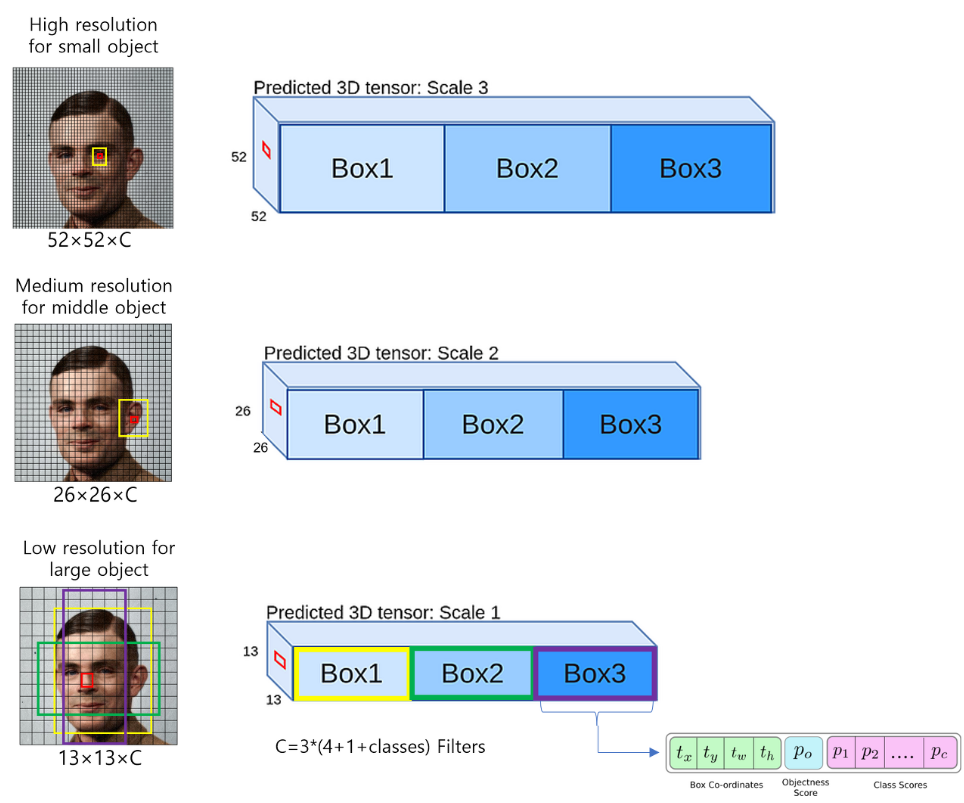
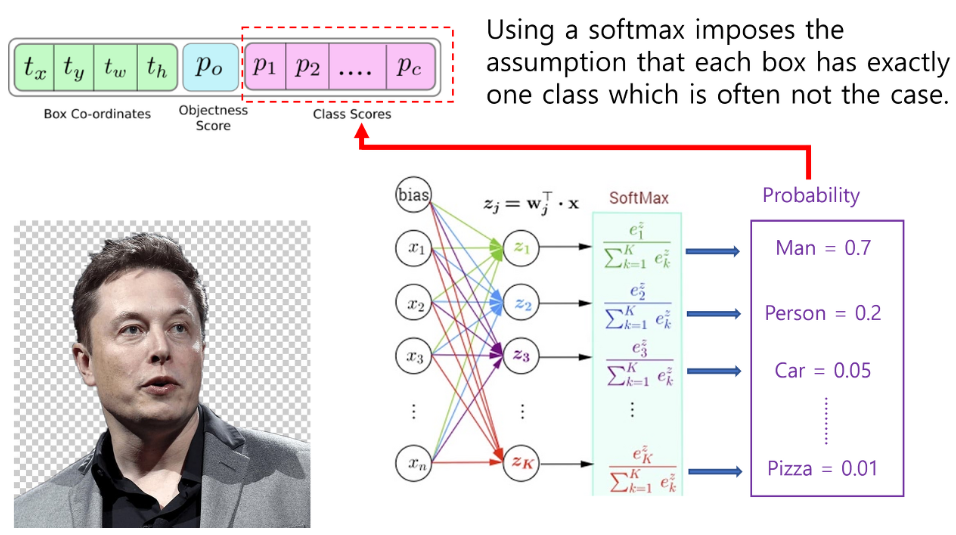
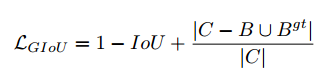이번에는 Focal Loss, IoU Loss에 대해 알아보겠습니다.
Focal Loss
Object Detection Loss
Object Detection에는 Localization과 Classification 두가지 절차가 있습니다.
Localization : Image에서 객체가 있을 만한 위치를 찾는 것.Classification : 어떤 물체인지 판단하는 것.
2 Stage는 Localization (ex : Selective Search, RPN ...) → Classification 순서로 진행
1 Stage는 Localization과 Classification이 동시에 처리
1 Stage는 2 Stage보다 처리 속도는 빠르지만 정확도면에서는 뒤떨어지는 경향이 있다고 합니다.
(그런데 요즘 1 Stage도 굉장히 좋아져서 잘 모르겠다.)
1 Stage의 정확도가 떨어지는 이유
Anchor Box가 가리키는 Location의 대부분은 학습에 기여하지 않는 Easy Negative 이므로 학습에 비효율적 .
easy negative 각각의 Loss 값은 작지만 굉장히 많으므로 전체 Loss 및 Gradient를 계산할 때, Easy Neagative의 영향이 압도적으로 커지는 문제가 발생 합니다.
※ easy negative란??
더보기
E asy Negative : 실제로 negative 이고 예측도 negative 라고 잘 나오는 예측이 쉬운 데이터 Hard Negative : 실제로는 negative 인데 positive 라고 잘못 예측하기 쉬운 데이터
Focal Loss는 1 Stage의 정확도가 떨어지는 단점을 보완 하 기 위해 제시된 Loss 입니다.
즉, Focal Loss는 Easy Negative와 Hard Negative에 대해 다른 가중치를 부여
Cross Entropy의 문제점
저번 게시글에서 Cross Entropy에 대해 다뤘었습니다.
Cross Entropy는 가중치를 다르게 부여한다는 점이 있었는데
Focal Loss와 어떤 점이 다른지 보겠습니다.
Binary Cross Entropy
이진분류를 예로 들면 Cross Entropy Loss 공식은 위와 같습니다.
\(Y_{act}\)는 \(Y\), \(Y_{pred}\)는 \(p\)로 표기를 하고
\(Y_{act}\)가 1이면 아래와 같은 식이 됩니다.
만약 \(p\)의 값이 1이면 \(CE(p,y) = 0\) 이 됩니다.
즉, 잘 예측했지만 보상은 없고 패널티도 없습니다.
반면, \(p\)의 값을 0에 가깝게 예측하게 되면 \(CE(p,y) ≈ ∞ \) 로 패널티가 엄청 커지게 되는 것입니다.
결론적으로 Cross Entropy 는 보상은 없고, 패널티만 부여 해주는 Loss Function
Easy Negative를 고려하지 않아 Easy Negative 의 영향을 많이 받습니다.
Focal Loss
이번에 알아볼 Focal Loss의 식을 보겠습니다.
Focal Loss
Focal Loss는 Easy Negative 의 영향을 줄이고 Hard Negative 의 학습에 초점을 맞추는 Cross Entropy의 확장판이라고 할 수 있습니다.
Focal Loss 식의 \(\alpha(1-p_{t})^{\gamma}\) 중 \(\alpha\) 와 \(\gamma\) 의 값은 논문에서 각각
\(\alpha = 0.25\) , \(\gamma = 2\) 를 최종적으로 사용
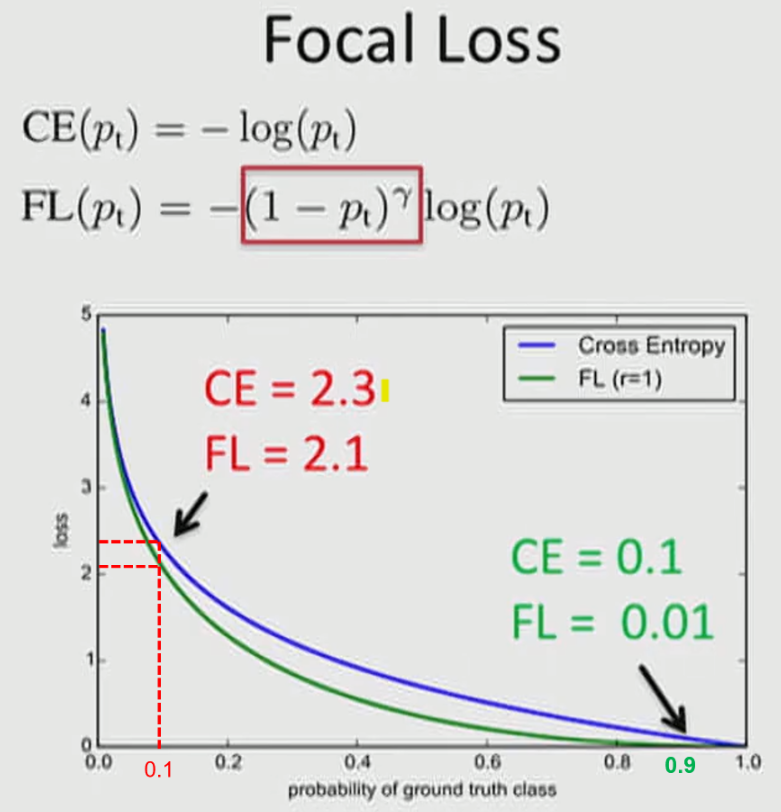
출처 : https://gaussian37.github.io/dl-concept-focal_loss/
x축의 빨간 0.1 (①) Hard Negative 문제이고, 초록색의 0.9 (②) Easy Negative 문제입니다.
\(\alpha\)와 \(\gamma\)는 1로 적용 되었습니다.
① 에서
\( CE(0.1) = -log(0.1) = 2.30259... \) 이고,
\( FL(0.1) = -(1 - 0.1)log(0.1) = 2.07233... \) 임을 알 수 있습니다.
② 에서
\( CE(0.9) = -log(0.9) = 0.105361... \) 이고,
\( FL(0.9) = -(1 - 0.9)log(0.9) = 0.0105361... \) 임을 알 수 있습니다.
Hard Negative 보다 Easy Negative의 경우 더 많이 떨어짐 을 통하여 기존에 문제가 되었던 수많은 Easy Negative 에 의한 Loss가 누적되는 문제를 개선
결론적으로 Focal Loss는 Cross Entropy 와는 다르게
Easy Negative에는 Hard Negative 보다 Loss를 더 크게 낮추는 보상
IoU Loss
IoU 란?
IoU는 Object Detection에서 Truth Box와 Predict Box의 차이를 나타낼 때 사용합니다.
그림과 같이 교집합 / 합집합
IoU 값은 0 ~ 1 사이의 값을 가지고 1로 갈수록 Truth Box에 가깝다는 얘기
IoU Loss
IoU Loss의 식은 위와 같습니다!
※ IoU 를 Loss에 이용하려는 이유!
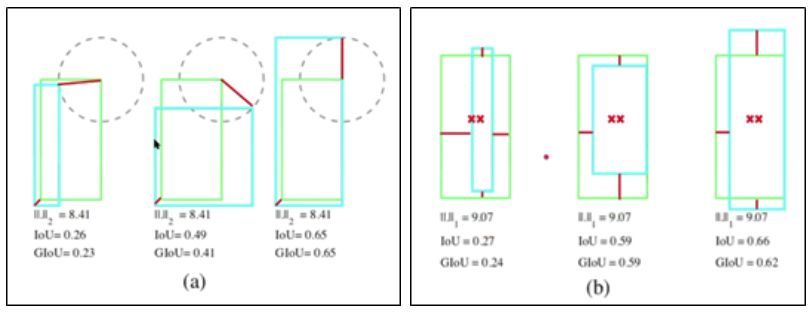
(a) 에서 볼 수 있듯이 MSE 값은 일정 하지만 box의 겹침 정도를 나타내는 IoU 값은 변합니다.
왼쪽 하단 거리와 오른쪽 상단 거리가 동일할 때
(b) 에서 볼 수 있듯이 MAE 값은 일정 하지만 box의 겹침 정도를 나타내는 IoU 값은 변합니다.
중심 사이의 거리와 높이, 너비 차이가 동일할 때
하지만 IoU를 Loss로 활용할때에도 문제점은 있습니다.
3번째 사진에서 보면 어느 정도의 오차로 교집합이 생기지 않은 것인지 파악을 할 수 가 없기 때문 입니다.
이러한 문제를 해결하기 위해 GIoU Loss 가 등장 합니다.
GIoU
GIoU
GIoU 는 IoU Loss의 문제점을 해결하기 위해서 새로운 Box를 하나 더 만들었습니다.
C Box는 A와 B Box를 포함한 가장 작은 Box 입니다.
위의 식에서 C\(A ∪ B) 는 C Box 영역에서 A와 B의 영역을 빼준 영역
GIoU Loss
위와 같이 구분이 가능합니다.
GIoU의 단점
초록색 : Ground Truth Box
검은색 : 기존 Anchor Box
파란색 : Predicted Box
GIoU Loss 사용에 따른 진행 방식이 너무 느림.
기존 AB 에서 GT 를 찾기 위해 PB 의 영역을 점점 넓혀 갑니다.
GT 와의 겹치는 부분이 생기면 IoU 값을 높이기 위해 PB 의 크기를 줄이며 점점 GT 에 가까워 지게 됩니다.
초록색 : Ground Truth Box
빨간색 : Predicted Box
요약하자면 수렴속도가 느리고, PB가 GB 안에 있으면 값이 Update 되지 않습니다.
DIoU
GIoU 의 문제점을 개선한 DIoU가 나왔습니다.
GIoU 가 PB의 영역을 넓히면서 학습되는 반면에
DIoU 는 GT와 PB의 중심점을 고려하여 학습을 진행 합니다.
DIoU
\( \rho \) : Euclidean distance
\( b \) : PB의 중심
\( b^{gt} \) : GT의 중심
\( c^{2} \) : CB의 대각 길이
CIoU
CIoU는 DIoU가 제안 된 논문
CIoU는 DIoU에서 aspect ratio (종횡비)를 고려한 Loss 입니다.
CIoU
\( \upsilon \) : 두 Box의 aspect ratio (종횡비)의 일치성을 측정하는 역할.
\( \alpha \) : non-overlapping case와 overlapping case의 균형을 조절하는 역할.
다음에는 어떤걸 알아볼까...
출처 :