딥러닝 기반의 얼굴 랜드마크 검출 모델
- heatmap regression
- 좋은 성능을 보임
- 연산이 비싸고, outlier에 민감함
- coordinate regression
- 빠르고 robust
- 정확도가 충분치 않음

다양한 환경에서 사용할 수 있고 효율적인 facial landmark detector인 PIP-Net(Pixel-In-Pixel Net) 제안
- three essential part
- Pixel-In-Pixel regression
- a neighbor regression module
- self-training with curriculum
PIP Regression
face landmark detector
- coordinate regression
- output이 길이 2N의 FC layer
- N : represents the number of landmarks
- heatmap regression
- input과 같은 해상도를 가지도록 추출된 feature map을 upsampling
- output heatmap은 N의 채널을 가짐
- 각각은 해당 랜드마크 위치의 가능성 반영
- coordinate regression이 연산 면에서 높은 효율성을 보이나, heatmap regression이 정확도 면에서 좋은 성능을 보임
- 연산의 비효율성에도 불구하고, heatmap 방식은 SOAT 정확도를 달성
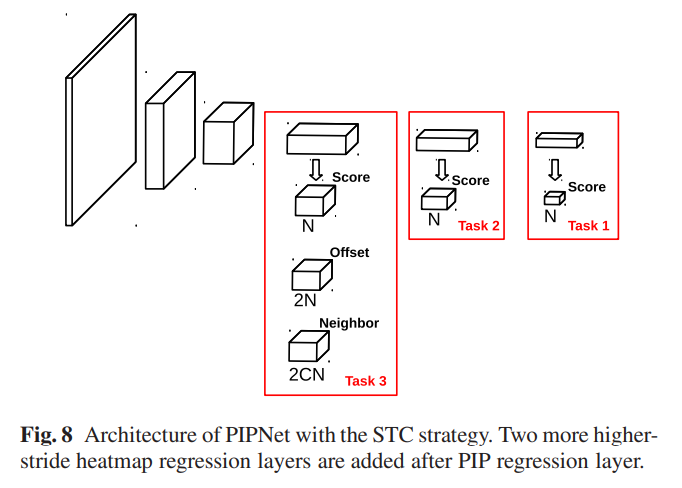
- 두 방식의 장점만을 가진 PIP regression 방식 제안
- heatmap regression 기반
- upsampling layer는 feature map에 point를 위치 시키는데 필요하지 않음
- low-resolution layer만으로도 localization하는데 충분
- low-resolution feature map을 적용함으로서 각 랜드마크에 대한 가장 가능성 높은 grid를 얻음
- grid의 왼쪽 상단 모서리를 기준으로 x축과 y축의 각 heatmap grid 내에서 오프셋 예측도 적용
- 점수와 오프셋 예측은 서로 독립적이므로 병렬로 계산 가능(single-stage method)
Neighbor Regression Module
- PIP-Regression은 Heatmap Regression의 효율성 문제를 해결하지만, 여전히 robust하지 못함
- 일관된 landmark 예측을 하는데 도움을 줄 수 있는 NRM(Neighbor Regression Module) 모듈 제안
- landmark offset 외에도 각 랜드마크는 C개의 neighbor offset을 predict
- NRM은 크기가 2CN × HM ×WM인 Neighbor map을 추가로 출력
- Face landmark의 mean shape은 학습 데이터의 ground-truth를 사용하여 계산하고 대상 랜드마크와 가장 가까운 C개의 랜드마크를 neighbor로 정의
Self-Training with Curriculum
- NRM은 PIP Regression의 불안정성을 완화하지만, crossdomain dataset에는 적합하지 않음
- 도메인 간 일반화 개선을 위해 레이블이 지정되지 않은 데이터를 추가로 사용하는 Self-Training with Curriculum 제안
- task의 난이도가 점차 증가하여 인간이 학습하는 방식을 모방
- task level에서 커리큘럼 학습 적용
- Pipeline of STC
- 수동으로 레이블된 data로 일반적인 방식으로 PIPNet 학습
- 학습된 detector를 통해 레이블 되지 않은 data터의 pseudo-label을 추정
- 수동으로 레이블된 data와 pseudo-label된 data로 새로운 학습 dataset 생성
- 새로운 dataset을 이용하여 PIPNet 학습
- 모델이 수렴할 때 까지 2~4 task 반복
'Deep Learning > Vision' 카테고리의 다른 글
| VieWorks 카메라 셋팅 (0) | 2023.07.17 |
|---|---|
| FaceBoxes 논문 정리 (0) | 2023.02.03 |
| 06. Vision Transform (작성중) (0) | 2022.05.13 |
| 05. Yolo 버전별 비교 (0) | 2022.05.13 |
| 04. Faster RCNN [Vision, Object Detection] (0) | 2022.02.09 |