합성곱 신경망 (CNN)

CNN은 위와 같이 Filter가 움직이며 이미지의 feature map을 추출하는 형식입니다.
즉, Filter를 한번 연산시 이미지의 전체를 고려하기 보다는 일부분만 고려하여 특성값을 추출합니다.
Low Level Layer (얕은 신경망)에서는 작은 패턴 Tiny Pattern - ex) edge, color
Hight Level Layer (깊은 신경망)에서는 전체적인 object를 봅니다.
예를 들면,
r1의 값은 x1, x2, x3으로 연산이 되고,
r2의 값은 x1, x2, x3으로 연산이 되고,
r3의 값은 x2, x3, x4로 연산이 이루어집니다. - 작은패턴
다음으로
p1은 r1, r2, r3로 연산이 이루어지는데 즉, p1은 x1, x2, x3, x4가 다 사용되는 겁니다. - 전체적인 object
구조적으로 간접적인 영향밖에 없기 때문에 이러한 국소적인 메커니즘이 전체를 봐야하는 경우에는 단점이 됩니다.
Attention
일단 Attention은 CNN에서 Filter를 사용하여 부분 부분 보는것과는 다르게
이미지의 전체를 봅니다.
1 x 1 Conv를 적용하면 전체의 이미지를 나타낼 수 있는 Feature Map이 생성이 됩니다.
이 Feature Map에 원본 이미지와 같은 크기, 각 픽셀마다의 중요도를 설정하여 곱셈을 하게 됩니다.
이것을 Attention이라고 합니다.
Key, Query, Value
Key, Query, Value는 Data Base에서 나온 개념입니다.
간단한 구조로 보겠습니다.
'a' : 1
'b' : 2
'c' : 3
위를 예시로 들면 'a', 'b', 'c' 는 각각 1, 2, 3 을 대표하는 값이고
원하는 데이터를 찾기 위해서 데이터 베이스에 요청을 보냅니다.
여기서
'a', 'b', 'c' = Key
1, 2, 3 = Value
요청 = Query
입니다.
즉, Vision Transformer 에서는 Query로 중요한 Key값만 불러오고,
Key에 따른 Value의 값을 구해오는 것입니다.
Transformer
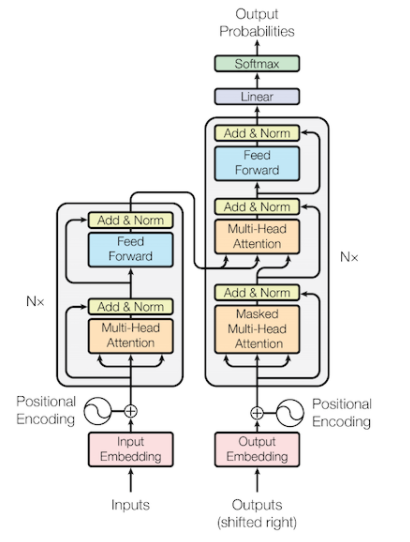
위의 사진은 일반적으로 자연어 처리에 사용되는 Transformer의 구조입니다.
크게 보면 왼쪽은 Encoder, 오른쪽은 Decoder입니다.
일단, Data의 예를 들어보겠습니다.
1) 저는 학생입니다.
2) I am a student.
1번 데이터는 Input 값이고, 2번 데이터는 Output 값입니다.
Train일때,
Encoder에는 1번 데이터가 들어가고, Decoder에는 2번 데이터가 들어가게 됩니다.
또한, 여기서 중요한 점은 Positional Encoding입니다.
Positional Encoding은 글자의 위치를 나타내주는 값입니다.
Test일때,
Encoder에는 1번 데이터가 들어가고, Decoder에는 빈 데이터가 들어가게 됩니다.
Positional Encoding: https://velog.io/@gibonki77/DLmathPE
[Transformer]-1 Positional Encoding은 왜 그렇게 생겼을까? 이유
트랜스포머의 입력은 RNN과 달리 한꺼번에 모든 요소가 들어가기 때문에, 위치관계의 패턴을 Encode해주는데요. 주로 사용되는 Sinusoidal Positional Encoding의 장점에 대해 알아보겠습니다.
velog.io
Vision Transformer
이제는 이미지에서의 Transformer를 살펴보겠습니다.
자연어 처리에서는 단어별로 끊어서 사용했다면, 이미지에서는 일정 크기로 분할을 하여 사용합니다.
예를 들어, 6x6 행렬을 3x3으로 나눈다고 하면
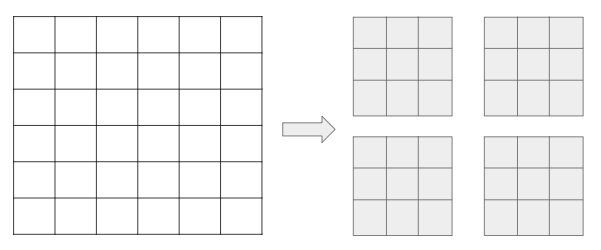
위와 같이 나누어서 Encoding을 해주는 것입니다.
여기서 어떠한 크기로 나눌것인지는 사용자 마음대로 정해줄 수 있습니다.
ex) 3 x 6 x 6 행렬이 있다면 3 x 4 x 3 x 3으로 나누어 주는 것입니다.
자른 이미지 하나하나를 패치라고 부릅니다.
Code
'Deep Learning > Vision' 카테고리의 다른 글
| PIP-Net 논문 정리 (0) | 2023.02.16 |
|---|---|
| FaceBoxes 논문 정리 (0) | 2023.02.03 |
| 05. Yolo 버전별 비교 (0) | 2022.05.13 |
| 04. Faster RCNN [Vision, Object Detection] (0) | 2022.02.09 |
| 03. Fast RCNN [Vision, Object Detection] (0) | 2022.01.21 |