Object Detection 분류
Object Detection에는 Localization과 Classification 두가지 절차가 있습니다.
- Localization : Image에서 객체가 있을 만한 위치를 찾는 것.
- Classification : 어떤 물체인지 판단하는 것.
2 Stage는 Localization (ex : Selective Search, RPN ...) → Classification 순서로 진행이 되고,
1 Stage는 Localization과 Classification이 동시에 처리합니다.
1 Stage는 2 Stage보다 처리 속도는 빠르지만 정확도면에서는 뒤떨어지는 경향이 있다고 합니다.
(그런데 요즘 1 Stage도 굉장히 좋아져서 잘 모르겠다.)
RCNN 계열은 2 Stage, Yolo는 1 Stage라고 보면 됩니다.
Yolo (You Only Look Once)

Yolo는 1 Stage Object Detection Model 입니다.
2 Stage인 RCNN 계열은 RPN을 통해 객체를 찾고, 그 부분을 따로 Classification 해줍니다.
즉, RCNN 계열보다 속도가 더 빠르기 때문에 실시간으로 이용하기에는 더욱 적절합니다.
버전별로 살펴보겠습니다.
Yolo v1
※ 특징
- Backbone : VGG 16
- Input Image를 7 x 7 의 Grid로 나눕니다.
- Bounding Box의 개수는 Grid당 2개씩 있습니다.
- 한 그리드당 (B x 5 + C) 크기의 Output 값이 나옵니다. → 최종 (7 x 7) x (B x 5 + C)
- B : 2개의 BBox 정보가 들어있다.
- x : Bounding Box의 중심 x좌표
- y : Bounding Box의 중심 y좌표
- w : Bounding Box의 너비
- h : Bounding Box의 높이
- confidence-score : Pr(Object)∗IoU
- C : 어느 특정 Class에 속하는지. (Class의 개수만큼의 크기로 나옴)
- ex) Class가 10이면 ( 0, 0, 1, 0, 0, ..., 0 )
- B : 2개의 BBox 정보가 들어있다.
- BBox가 2개이지만 한 Grid당 Object 하나만 Detection 가능합니다.
- 위의 설명과 같이 2개의 BBox 정보가 들어있지만, Class는 하나밖에 없습니다.
※ Yolov1 의 문제점
- 여러 물체들이 겹쳐있으면 제대로 된 예측이 어렵습니다. - 하나의 Grid 당 하나의 Object
- 물체가 작을수록 정확도가 감소합니다.
- 학습할때 사용된 BBox와 크기가 많이 다른 형태는 정확히 예측하지 못합니다.
Yolo v2
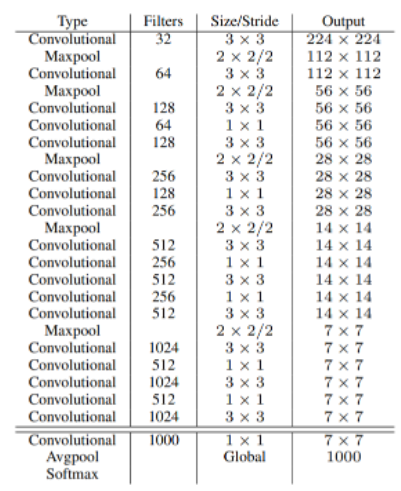
※ 특징
- Backbone : Darknet 19
- Input Image를 13 x 13 의 Grid로 나눕니다.
- Yolov1에서 사용되었던 Fully connected 사라집니다.
- BatchNormalization 사용합니다.
- 위 사진의 노란 부분을 추가함으로써 작은 Object도 Detection 할 수 있도록 했습니다.
- Grid 당 Anchor Box 5개 씩
- Anchor Box : Grid당 여러개의 Bounding Box를 배치 - 아래 사진은 예시!
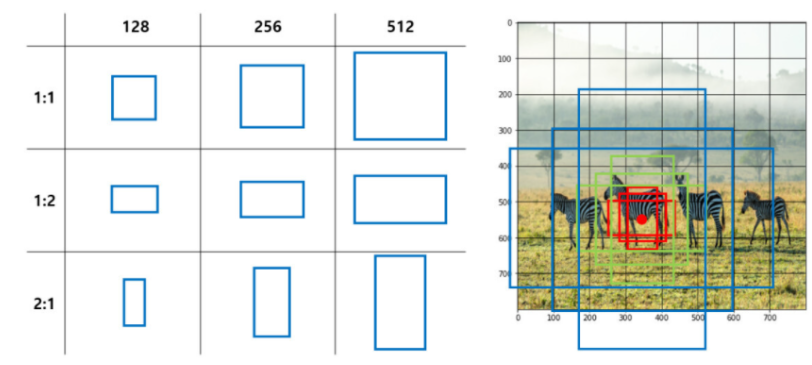
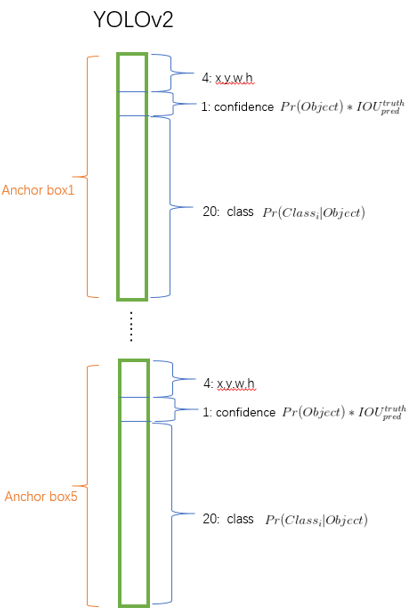
- Yolo v1과는 다르게 하나의 Grid에서도 여러 객체를 Detection 할 수 있습니다.
- Output shape : 13 x 13 x B(5 + C)
- 즉, Yolo v1과는 다르게 모든 BBox에 대한 정보를 Output으로 가집니다.
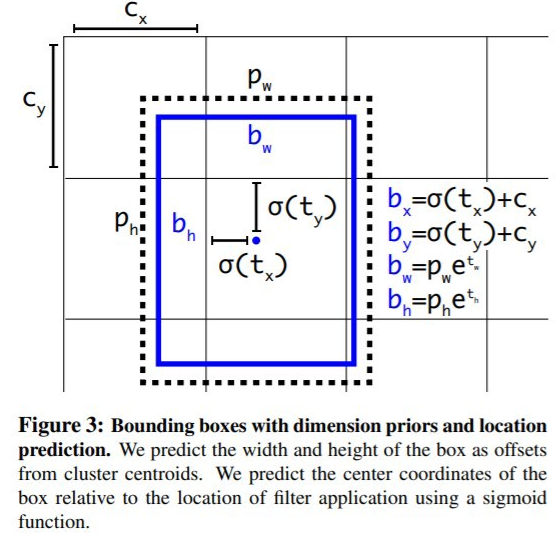

- Bounding Box Regression : Anchor Box의 좌표를 객체에 더욱 알맞게 조정해줍니다.
- σ(x) : sigmoid(x)
- Cx,Cy : Grid cell의 좌상단 끝의 offset
- pw,ph : Anchor Box의 width, height
- bx,by : GT에 가까워지도록 계속해서 학습되는 trained anchor box의 중심 좌표
- tx,ty,tw,th : 5개의 Anchor Boxes 각각의 좌표
- 학습을 진행하며 tx,ty,tw,th 는 GT와의 차이가 0이 되게 수렴되게 됩니다.
Yolo v3
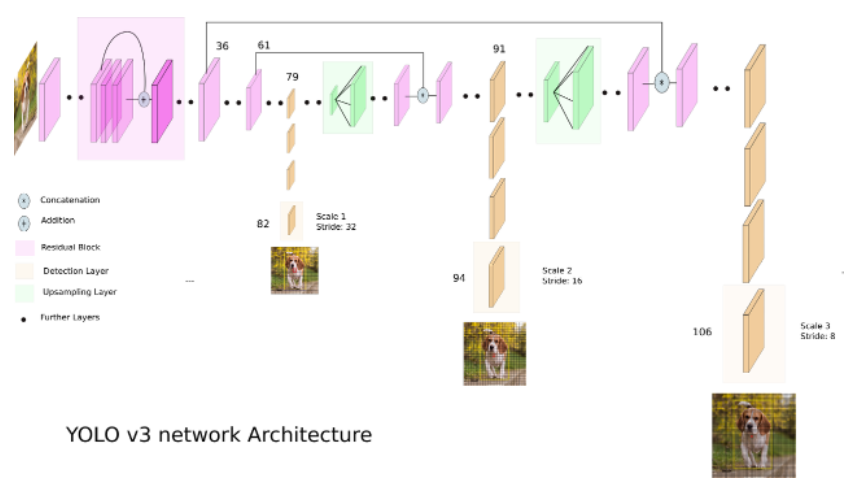
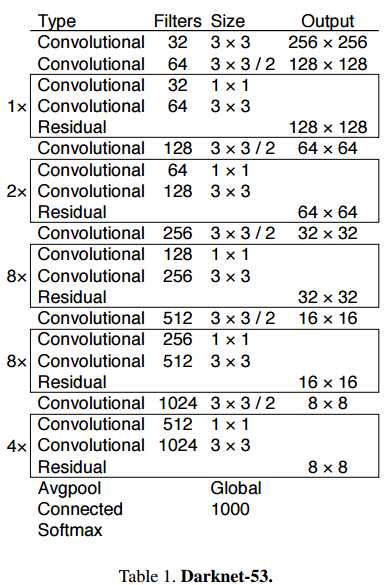
※ 특징
- Backbone : Darknet 53 (Darknet 19의 발전된 버전)
- Grid 당 비율과 크기가 다른 9개의 Anchor Box 사용합니다.
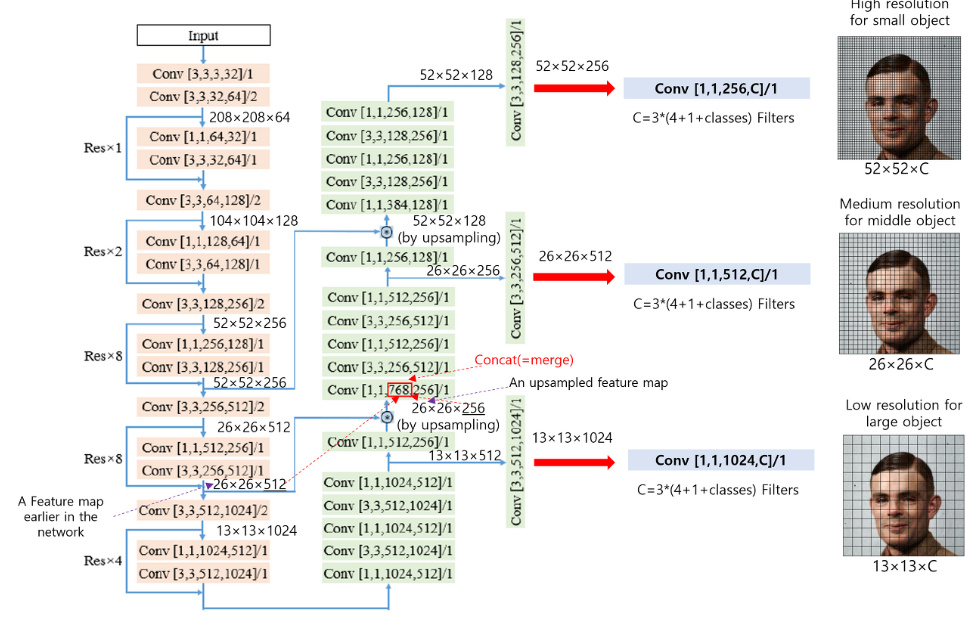
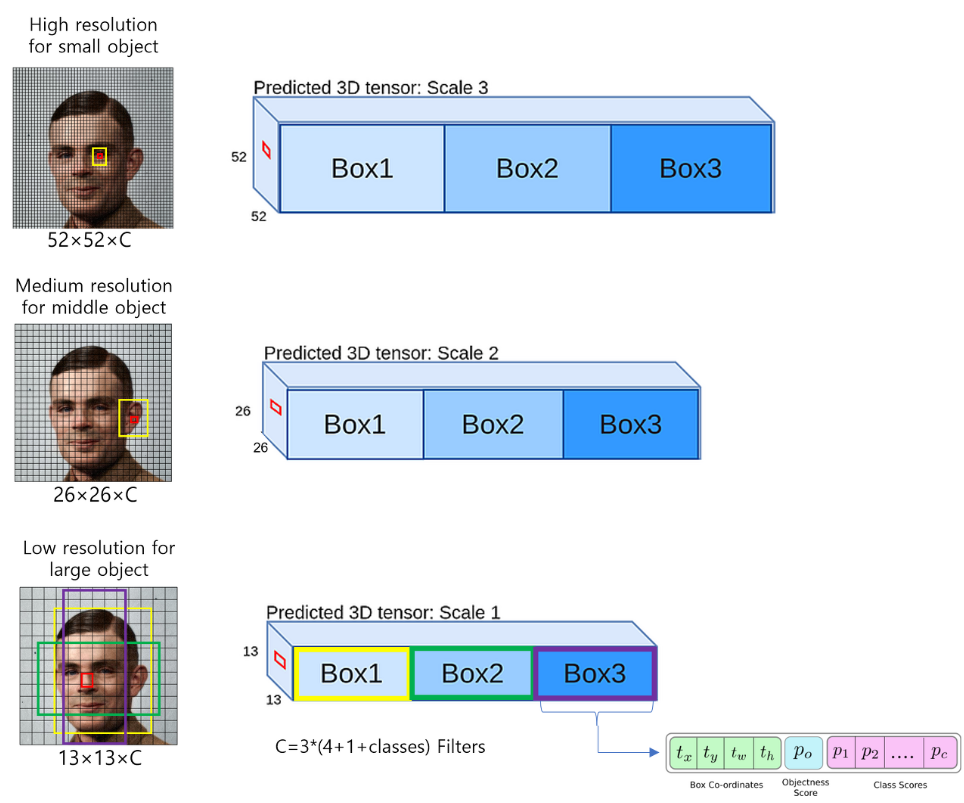
- 여러 Scale에서 나온 값을 사용합니다.
- 작은 Object도 탐지 가능!
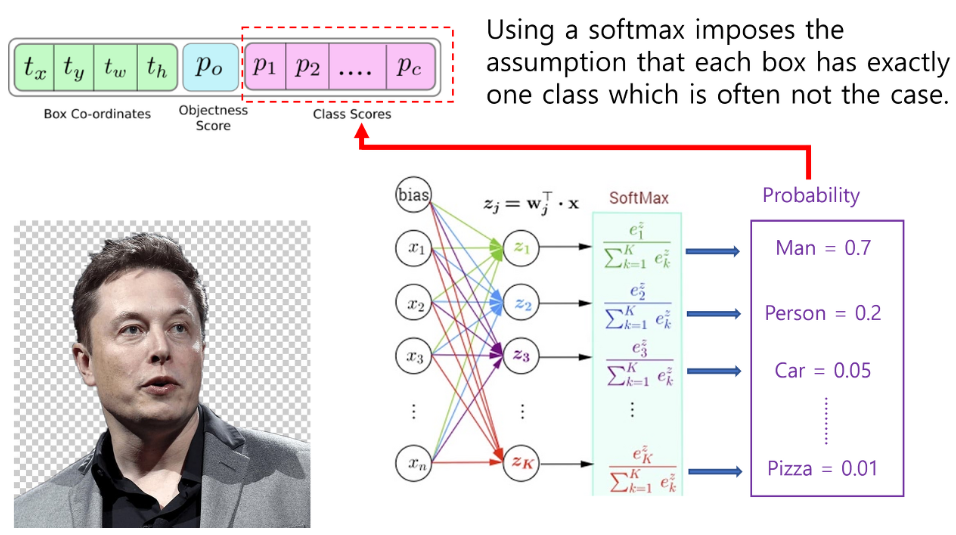
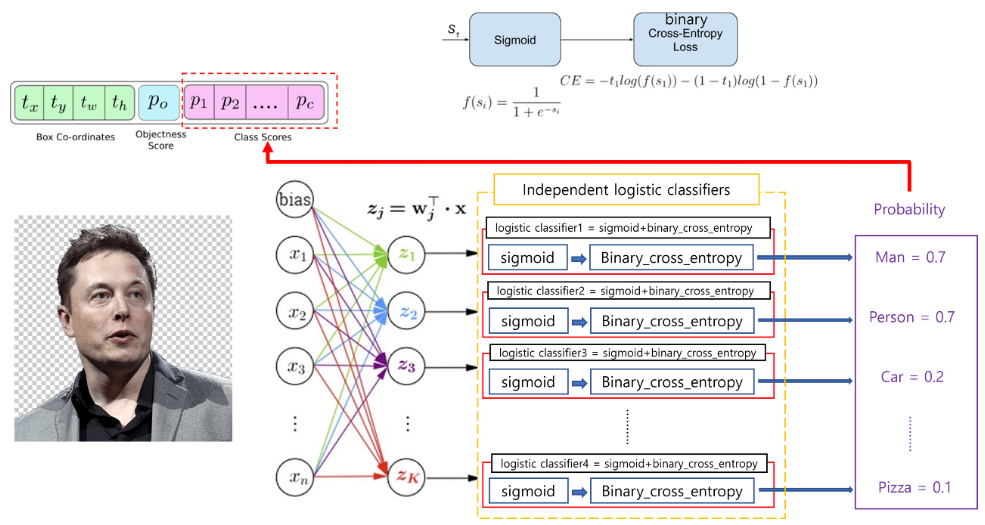
- Softmax는 제일 높은 하나의 클래스 확률 값만 높게 설정해 주기 때문에 Sigmoid → Binary cross entropy (Independent logistic classifiers)를 취해줍니다.
- input으로 남자 사람의 이미지가 들어갔다고 가정했을때, 만약 Class의 종류 중 'Person'과 'Man'이 있다면 둘 중 하나의 값이 나오게 됩니다. 이 이유는 입력 이미지에는 하나의 클래스만 있을 것이라는 가정을 하기 때문입니다. 그래서 정확하게 예측하기 위해 Independent logistic classifier를 사용해줍니다.
- Focal Loss 적용하려고 했지만 성능이 저하되서 Focal Loss를 사용하지 않았습니다.
출처 :
- https://junha1125.github.io/blog/artificial-intelligence/2020-08-18-YOLO/
- https://wsthub.medium.com/how-does-yolov2-work-daaaa967c5f7
- https://herbwood.tistory.com/17
- https://89douner.tistory.com/93
'Deep Learning > Vision' 카테고리의 다른 글
| FaceBoxes 논문 정리 (0) | 2023.02.03 |
|---|---|
| 06. Vision Transform (작성중) (0) | 2022.05.13 |
| 04. Faster RCNN [Vision, Object Detection] (0) | 2022.02.09 |
| 03. Fast RCNN [Vision, Object Detection] (0) | 2022.01.21 |
| 02. SPP-Net [Vision, Object Detection] (0) | 2021.11.17 |