Loss Function
손실함수(Loss Funtion)은 예측 값이 실제 값과 얼마나 유사한지 판단하는 기준이 되는 함수입니다.
예측 값과 실제 값의 차이를 loss라고 하며, 이 loss를 줄이는 방향으로 학습이 진행됩니다.


예를 들어, 왼쪽의 그림에서 파란점이 실제 값이라고 가정하고 파란 점선을 예측 값이라고 가정하겠습니다.
그렇다면 실제 값과 예측 값의 차이를 계산하고 이 차이를 줄이기 위해 경사하강법과 같은 optimizer를 사용하는 것입니다.
※ Optimizer 정리글 : https://ggongsowon.tistory.com/99
Loss Function 종류
보통 Loss Function은 무슨 약자인지 알면 금방 파악할 수 있습니다.
1. 평균 절대 오차 (MAE, Mean Absolute Error)


MAE는 이름과 같이 예측 값과 정답 값의 차이에 절댓값을 취하여, 그 값들의 평균을 내줍니다.
- 다른 Loss Function과 비교했을때 outlier의 영향을 상대적으로 크게 받지 않습니다.
- 미분 불가능한 지점이 있습니다. (첨점 - 0 부분)
- 모든 오차에 동일한 가중치를 부여합니다.
2. 평균 제곱 오차 (MSE, Mean Square Error)


MSE는 MAE와는 다르게 절댓값이 아닌 제곱을 해줍니다.
- 이상치에 대해 민감하다. 즉, 오차가 크면 클수록 크게 반영됩니다.
- 오차값이 0~1 사이는 더 작게, 1 이상은 더 크게 반영됩니다.
- 모든 함수값이 미분 가능합니다.
3. 평균 제곱근 오차 (RMSE, Root Mean Square Error)


RMSE는 MSE에 root를 사용했습니다.
- MSE보다 이상치에 대해 덜 민감하다.
- 미분 불가능한 지점이 있습니다. (첨점 - 0 부분)
3가지 Loss Function 비교
- MSE는 이상치에 대해 너무 민감하여, 모델의 학습을 불안정하게 만들 가능성이 크다. 현실 세계에서 마주하는 많은 데이터에는 이상치가 있고, 그 중 어떤 경우에 이상치가 처리되지 않을 때가 있는데, 그러한 경우 MSE를 이용한다면, 이상치에 민감하게 학습되기 때문에 학습 과정이 불안정할 것이다.
- MSE에 루트를 취하여 이상치에 대한 민감도를 줄인 RMSE와 절대값을 취하는 MAE의 차이
- MAE는 오차들의 절댓값의 평균을 계산한다는 점에서, 모든 오차에 동일한 가중치를 부여한다.
- RMSE는 각 example에 제곱을 취한 뒤 평균을 구하고, 그것에 루트를 씌우는 것이기 때문에, 각 오차가 다른 가중치를 갖는다.

왼쪽의 MAE는 값의 범위 상관 없이 동일하게 가중되어 있습니다.
하지만 오른쪽의 RMSE는 0~1 사이의 오차는 더욱 작게, 1 초과의 값들은 더욱 크게 가중되어집니다.
이렇게 해서 얻는 이득은 아래와 같습니다.

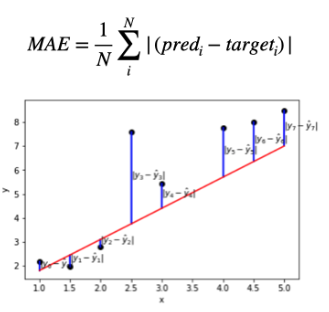
검은점은 예측값, 빨간선이 정답값, 파란선은 오차 입니다.
MAE 식을 적용해보면 1.375라는 값이 나오고
RMSE 식을 적용하면 1.70이라는 값이 나오게 됩니다.
즉, RMSE는 오차값에 따라 적용되는 가중이 달라서 큰 오차값이 있게 되면 Loss 값은 올라가게 됩니다.
출처:
'Deep Learning > deep learning' 카테고리의 다른 글
| 06_Loss Function_3_Focal Loss, IoU Loss (0) | 2022.05.11 |
|---|---|
| 06_Loss Function_2_Entropy, Binary, Categorical (0) | 2022.05.04 |
| 05_Overfitting, Regularization (0) | 2022.04.18 |
| 04_Max Pooling (0) | 2022.04.18 |
| 03_Batch Nomalization 배치 정규화 (0) | 2022.04.06 |