이번 게시글은 GoogLeNet에 대해 알아보겠습니다.
GoogLeNet은 2014 ILSVRC Competition에서 우승을 했습니다.
하지만 우승을 한거에 비해서는 준우승을 한 VGG보다 널리 활용되지 못했습니다.
일단 GoogLeNet의 모델 구조 사진을 보겠습니다.

다른 모델들의 구조들과 달리 굉장히 복잡한게 눈에 보입니다.
이 모델을 보기 전에 여러 개념을 알고 가야하기 때문에 먼저 여러 개념부터 잡고 가겠습니다.
1 x 1 Convolution

GoogLeNet에서 사용된 1 x 1 Convolution입니다.
1 x 1 Convolution은 Feature Map의 갯수를 줄이는 목적으로 사용됩니다.
즉, Feature Map의 갯수가 줄어서 연산량을 낮추는 겁니다.
연산량을 낮추면 Layer를 더 깊게 쌓을 수 있습니다.
예를 들어보겠습니다.
※ Convolution 계산: https://ggongsowon.tistory.com/9
Example)
14 x 14 x 480 Feature Map이 있다고 가정을 해보겠습니다.
이것에 48장의 5 x 5의 Filter, padding = 2, stride = 1로 Convolution을 해주면
14 x 14 x 48 의 Feature Map이 생성됩니다.
그렇다면 이때 필요한 연산량은
※ (14 x 14 x 48) x (5 x 5 x 480) = 112,896,000 = 112.9M이 됩니다.
그렇다면 이제 1 x 1 Convolution을 사용해보겠습니다.
14 x 14 x 480 Feature Map이 있다고 가정을 해보겠습니다.
이것에 16장의 1 x 1의 Filter, padding = 0, stride = 1로 Convolution을 해주면
14 x 14 x 16 의 Feature Map이 생성됩니다.
그리고 48장의 5 x 5의 Filter, padding = 2, stride = 1로 Convolution을 해주면
14 x 14 x 48 의 Feature Map이 생성됩니다.
여기서도 똑같이 연산량을 계산해 보겠습니다.
⑴ (14 x 14 x 16) x (1 x 1 x 480) = 1,505,280 = 1.5M
⑵ (14 x 14 x 48) x (5 x 5 x 16) = 3,763,200 = 3.8M
※ ⑴ + ⑵ = 5.3M
두 값을 비교해보면 대략 21배 정도 차이가 납니다.
Inception Module
다음은 Inception Module 입니다.
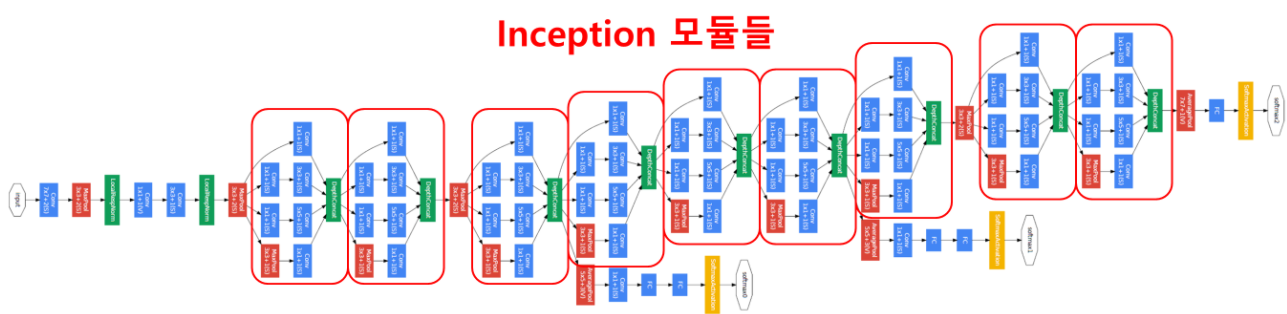
GoogLeNet에는 총 9개의 Inception모듈이 사용되었습니다.
Inception 모듈은 다양한 특성 값들을 추출해내기 위한 과정이라고 볼 수 있겠습니다.
이제 하나를 확대해서 살펴보겠습니다.

GoogLeNet에서는 (b)를 사용하였고 1 x 1 Convolution이 추가된 layer입니다.
1 x 1 Convolution을 사용한 이유는 위에서 설명했다시피 연산량을 줄여주기 위해 사용되었습니다.
Inception 모듈에서는 1 x 1, 3 x 3, 5 x 5, 3 x 3 max pooling를 통해 다양한 특성값들을 추출해냅니다.
여기에서 max pooling에도 1 x 1 Convolution을 해주었는데
이는 Previous layer에서 Concat 연산시 채널값을 맞춰주기 위함입니다.
Global Average Pooling

이전 게시물에서 다뤘던 Model들은 FC 방식으로 마지막 부분의 Layer를 채워줬지만
GoogLeNet에서는 Global Average Pooling 방식을 사용하였습니다.
Global Average Pooling은 각 채널에서의 특성맵들을 각각 평균낸 것을 이어서 1차원 vector로 만들어 주었습니다.
이것도 연산량을 줄이기 위해 사용되었습니다.
Auxiliary Classifier
Train을 하다보면 Gradient Vanishing 현상이 발생할 수도 있습니다.
※ Gradient Vanishing: https://ggongsowon.tistory.com/42
13_Pytorch_Activation_Gradient Vanishing
저희가 저번시간에는 XOR 문제를 해결해 보았습니다. XOR를 사용하기 위해서 Perceptron 사이사이 Sigmoid를 사용해 주었습니다. 이런 함수들을 Activation Function이라고 부릅니다. 다음 Layer로 값이 넘어
ggongsowon.tistory.com
이를 위해 GoogLeNet에서는 중간중간에 softmax를 두어 중간에서도 Backpropagation이 발생하게 해주어
Gradient가 잘 전달되지 않는 문제를 해결하였습니다.
※ Auxiliary Classifier 주의사항
- Backpropagation시, weight값에 큰 영향을 주는 것을 막기 위해 Auxiliary Classifier에 0.3을 곱함.
- 맨 마지막 softmax는 따로 value를 곱해주지 않음.
- Inference 과정에서는 Auxiliary Classifier를 모두 제거한 후 사용, weight값을 업데이트 해주지 않기 때문.
Code








※ 출처:
☆ https://www.youtube.com/watch?v=uQc4Fs7yx5I&t=39s
https://github.com/pytorch/vision/blob/main/torchvision/models/googlenet.py
https://www.vlfeat.org/matconvnet/models/imagenet-googlenet-dag.svg
'Deep Learning > Pytorch' 카테고리의 다른 글
| 32_DenseNet (0) | 2022.04.11 |
|---|---|
| 31_ResNext (0) | 2022.04.08 |
| 30_AlexNet (0) | 2022.03.01 |
| 27_Pytorch_Custom_Dataset (0) | 2021.12.02 |
| 23_Pytorch_EfficientNet (0) | 2021.11.24 |