게시 순서가 조금 이상하지만 AlexNet에 대해 리뷰하겠습니다.
AlexNet의 구조

일단 AlexNet이 나올 시기에는 GPU가 현재 GPU만큼 좋지 못했습니다.
그래서 논문 저자들은 많은 데이터를 다루기 위해서 2개의 GPU를 사용했습니다.
논문에 나와있는 빨간색 박스 부분이 이해가 가지 않아 github 검색중 위와 같은 형태로
모델을 구성한 코드를 발견할 수 있었습니다.
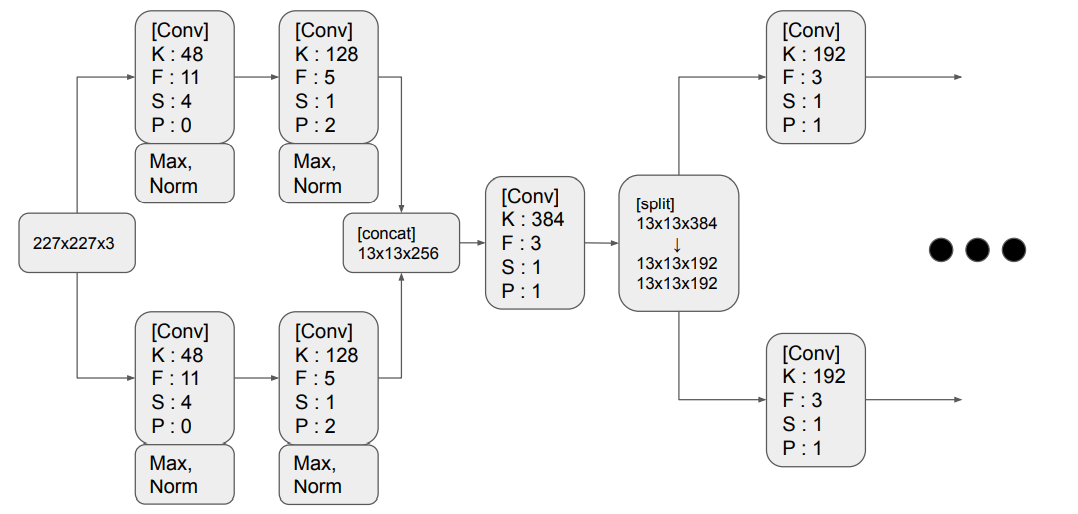
아래의 github를 참고삼아 나름대로 정리를 해보았습니다.
논문에서 공유한다는 의미를 concat과 split를 이용하였습니다.
참고 자료: https://github.com/demul/AlexNet/blob/master/model.py
ReLU
본 논문에서는 ReLU를 사용하여 sigmoid나 tanh보다 성능을 높였다고 나와있습니다.

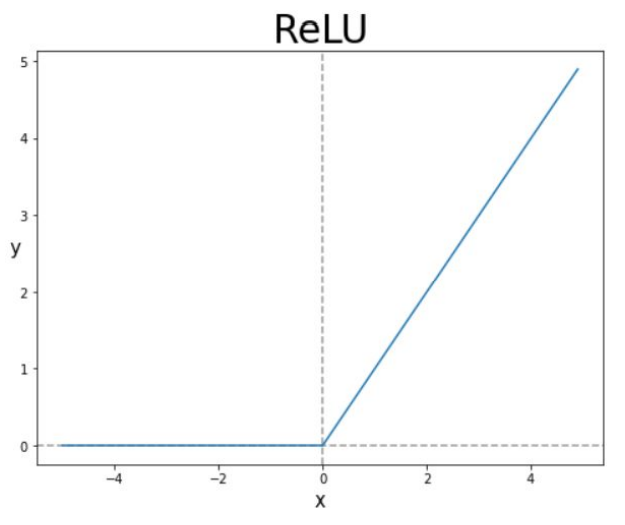
ReLU는 0 미만의 값은 0으로 수렴하고, 0 이상의 값은 f(x) = x 로 수렴하게 됩니다.
ReLU의 문제점을 해결하기 위해 LeakyReLU 와 같은 Activation도 나왔으니 시간이 되면 정리를 해보겠습니다.
Local Response Normalization (LRN)
LRN은 현재는 잘 사용되지 않고 있는 방법으로 알고 있습니다.

위와 같은 식으로 이루어져 있고 자세한 정보를 얻고 싶다면 아래의 링크를 이용하는것이 좋아보입니다.
참고자료:
Overfitting
AlexNet에서는 Overfitting을 예방하기 위해 Data Augmentation과 Dropout을 이용했다고 나와있습니다.


Code

'Deep Learning > Pytorch' 카테고리의 다른 글
| 31_ResNext (0) | 2022.04.08 |
|---|---|
| 25_Pytorch_GoogLeNet 1x1 Convolution (0) | 2022.03.15 |
| 27_Pytorch_Custom_Dataset (0) | 2021.12.02 |
| 23_Pytorch_EfficientNet (0) | 2021.11.24 |
| 26_Pytorch_Inception-v2, v3 (미완) (0) | 2021.10.25 |