Convolution

고양이가 어떠한 이미지를 바라볼때 모든 뉴런들이 동작하는 것이 아니라 이지미의 특정부분에 대해서 일부분의 뉴런만 동작하는 것에서 착안하여 나온것이 Convolution입니다.
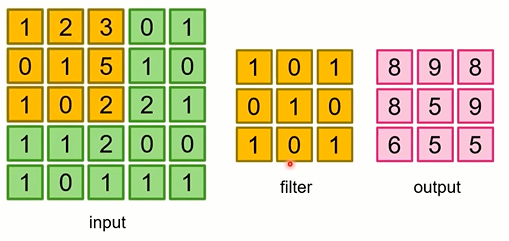
32 * 32 * 3 사이즈의 이미지가 있다고 가정을 해보겠습니다.
※ 여기서 3이라는 숫자는 이미지가 흑백인지 컬러인지를 나타내주는 값입니다. R, G, B 각각 하나씩이라고 보면 될것같습니다.
위에서 언급했던 이미지의 일부분의 특징값을 뽑아낼 수 있는 neuron의 역할을 할 수 있는
filter를 이용하여 특징값을 추출해줍니다.
filter를 이미지에서 이동을 시키며 하나의 값들로 추출하여 특징값을 가진 이미지를 만들어줍니다.
※ 같은 filter로 특징값을 추출해줍니다!
Convolution 연산
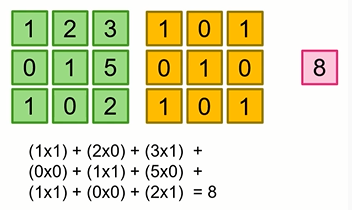
값을 추출해주는 연산입니다.
단순히 행렬 연산의 곱이 연속된 것이라고 생각하면 됩니다.
여기서 filter를 Wx + b에서 W값이라고 보시면 되겠습니다.
또한 filter를 한칸씩 이동하면서 연산을 하게 되는데 이때 stride=1 이라고 합니다.
즉, 5 * 5 이미지에 3 * 3 filter를 적용하게 되면 3 * 3의 특징값들이 나오게 됩니다.
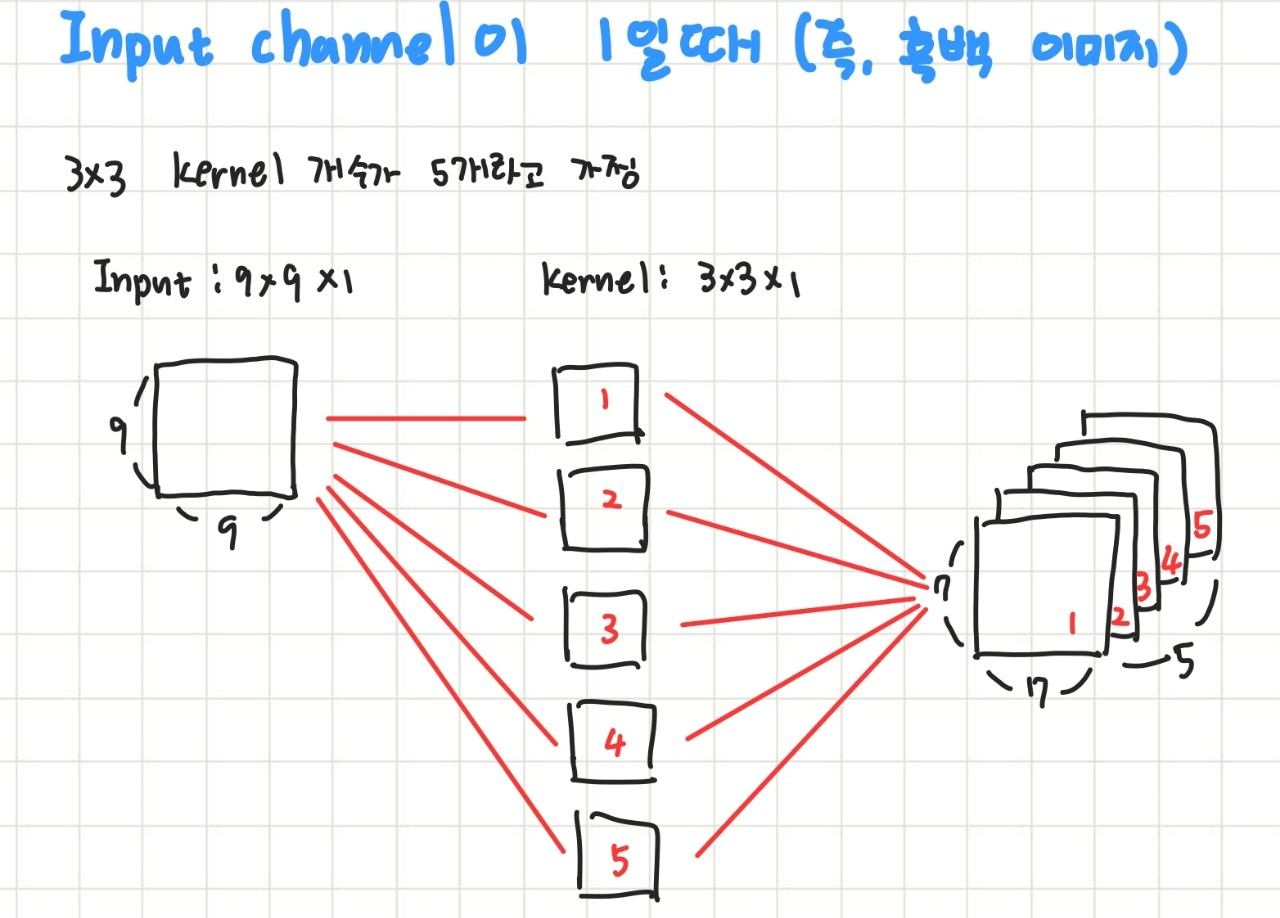
여러 채널을 가진 Input Data에서의 Convolution 연산

Convolution은 Filter (Kernel) 하나당 하나의 Feature Map이 나오게 됩니다.

Neuron과 Convolution
kernel은 위에서 말했던 것처럼 Weight값입니다.
Padding
위의 Convolution 연산을 진행하다 보면 이미지가 계속 작아지게 됩니다.
그렇게 되면 이미지가 작아지는 만큼 이미지에 대한 정보를 잃어버리게 된다는 뜻도 됩니다.
특히, 모서리 부분의 정보를 잃어버리게 되는데 이를 위해 Padding이라는 것이 등장했습니다.

위의 사진과 같이 이미지를 0으로 감싸주는 것입니다.
이를 함으로써 모서리 부분의 특징값들을 살리면서 이미지가 급격하게 작아지는 것을 방지해줍니다.
※ Convolution의 Output 크기 계산 예시!
https://ggongsowon.tistory.com/9
Pytorch Conv Output_Size 계산
nn.Conv2d(3, 32, 3, padding=1) 첫번째 parameter 인 3은 input_channel_size가 되겠습니다. 여기서 input_channel_size는 Input Image의 RGB depth 인 3이 되겠습니다. (즉, 32*32 Image 3장이 들어간다고 보면..
ggongsowon.tistory.com
Pooling Layer (sampling)

Conv Layer에서 한 Layer씩 뽑아 sampling을 해줍니다.
ex) channel이 3이면 3장중 한장씩 뽑아서 sampling
Pooling에서는 Max Pooling, Avg Pooling 등이 있습니다.
여기서 Max Pooling을 살펴보겠습니다.

보시는 것과 같이 filter 내에서 가장 큰 특징값을 추출하여 새로운 이미지를 만들어 줍니다.
Avg는 말 그대로 평균값을 이용해주는 것입니다.
Code


Pytorch에서 Conv2d를 사용하기 위한 함수입니다.
- in_channels = filter의 개수
- out_channels = output의 개수
- kernel_size = filter의 행렬 크기
- stride = filter의 이동 칸수
- padding = padding의 사이즈
- dilation = filter 사이 간격 사이즈
- groups = 입력 채널들을 여러 개의 그룹으로 나누어 독립적인 컨볼루션을 수행

출처:
https://www.youtube.com/watch?v=Em63mknbtWo&list=PLlMkM4tgfjnLSOjrEJN31gZATbcj_MpUm&index=35
https://www.youtube.com/watch?v=rySyghVxo6U&list=PLQ28Nx3M4JrhkqBVIXg-i5_CVVoS1UzAv&index=19