Weight Initialization
이전 글에서 Gradient Vanishing을 해결하기 위해서 Activation Function을 ReLU로 바꿨습니다.
그리고 여기 Gradient Vanishing을 해결하기 위한 방법이 또 한가지 있습니다.

ReLU를 똑같이 사용했는데도 학습과정에서 속도가 차이가 나는것을 알 수 있습니다.
이것은 Weight 값을 입력할때 보통 랜덤값을 넣고 실행하기 때문입니다.
여기서, Weight값을 0으로 초기값으로 진행을 한다면
Backpropagation을 진행할때 기울기가 0이 되므로 Gradient Vanishing 현상이 일어납니다.
그래서 우리가 초기값을 0을 사용하면 안되고 (학습이 진행이 안됨) Weight의 초기값을 정해주기 위해
RBM(Restricted Boatman Machine)이라는 방법이 나옵니다. (현재는 많이 사용하지 않음)
RBM

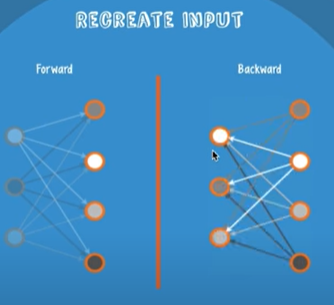
학습을 수행하는데 있어 Forward와 Backward를 진행하게 됩니다.
endcoder, decoder라고도 부를 수 있습니다.

Forward와 Backward 진행 후 input 값을 서로 비교하여 일치하게 만들어주는 Weight값들을 찾아주는 겁니다.
여러 Layer가 있다면 두개의 Layer씩 비교를 하며 마지막 Layer까지 진행을 해줍니다.
※ RBM 적용 후 학습을 시킬때
이를 학습이라고 하지 않고 Fine Tuning이라고 합니다.
그 이유는 Weight들을 값만 바꿔주는 Tuning만 해주면 되기 때문입니다.
RBM을 사용하기에는 너무 복잡하기 때문에 Xavier Initialization이라는 방법이 나오게 됩니다.
Xavier Initialization

Xavier Initialization은 input(fan_in)과 output(fan_out)의 개수에 따라
2010년에는 위의 수식대로 Weights값을 주어지면 되는 것입니다.
2015년에는 위의 수식대로 Weights값을 주어지면 되는 것입니다.
이제 코드로 직접 사용해보겠습니다.
이전글의 Model 선언부 입니다.

여기에서 달라진건 __init__ 함수 부분의 마지막인
torch.nn.init.xavier_uniform_(self.linear4.weight) 입니다.
위와 같이 적용해주면 됩니다.
'Deep Learning > Pytorch' 카테고리의 다른 글
| 16_Pytorch_Batch_Normalization (0) | 2021.09.29 |
|---|---|
| 15_Pytorch_Overfitting_Dropout (0) | 2021.09.14 |
| 13_Pytorch_Activation_Gradient Vanishing (0) | 2021.09.08 |
| 12_Pytorch_Multi_Layer_Perceptron_XOR (0) | 2021.08.25 |
| 11_Pytorch_Backpropagation (0) | 2021.08.25 |