Shared Memory를 사용하기 위한 방법은 두가지 있습니다.
- User-managed cache ★ 중요
- 유저가 관리하는 cache
- 읽는 데이터 Block을 cache에 가져다 놓음으로써 Memory Access 시간을 줄입니다.
- L1 cache
User-Managed Cache

※ Device Memory = Global Memory
Shared Memory에 자주 사용하는 Data를 올려놓음으로써 Global Memory의 Access를 줄여주는것입니다.

Example
행렬 A(row x k)와 B(k x col) 의 곱을 예로 들어봅니다.
여기서 Thread Layout을 잡을 때는 출력을 기준으로 합니다.
즉, 행렬 C를 기준으로 계산을 해줍니다.
C는 32 by 32 행렬입니다.
32 x 32 = 1024이므로 하나의 Block으로 처리가 가능합니다.
row = threadIdx.y → y축으로 행이 몇개 이동했는지
col = threadIdx.x → x축으로 열이 몇개 이동했는지
행렬 A안에 하나의 행에 있는 인자값들의 수는 k개
행렬 B안에 하나의 열에 있는 인자값들의 수는 k개
즉, k로 for문을 만들면 됩니다.
HOST(CPU)에서의 로직, Kernel(GPU)에서의 로직을 비교했습니다.
여기서 한줄 한줄 자세히 살펴보겠습니다.
행렬 C의 계산될 row, col 위치 구하기! (9~10번째 line)

row는 행이고 행렬 C의 왼쪽 맨위를 기준으로 세로방향 즉, y축으로 움직입니다.
그러므로 row = threadIdx.y 가 되고
col은 열이고 행렬 C의 왼쪽 맨위를 기준으로 가로방향 즉, x축으로 움직입니다.
그러므로 col = threadIdx.x 가 됩니다.
행렬 C의 index 구하기! (11번째 line)

하나의 행의 사이즈는 blockDim.x이고,
우리가 원하는 행의 위치는 threadIdx.y 입니다.
즉, blockDim.x * threadIdx.y 행에 우리가 원하는 thread가 있습니다.
그리고 여기서 원하는 열의 위치는 threadIdx.x 이므로
blockDim.x * threadIdx.y + threadIdx.x 가 최종적으로 우리가 원하는 thread의 위치입니다.
※ row = threadIdx.y, col = threadIdx.x
13번째 line
여기는 행렬 C의 index 부분을 초기화 해주는 부분입니다.
14번째 line

행렬 C는 k by k 사이즈의 행렬입니다.
그래서 k를 기준으로 for문을 실행해줍니다.
행렬 C의 index값 구하기! (15번째 line)
일단 행렬 곱을 알고 있다는 전제하에 시작하겠습니다.
행렬 곱을 구하기 위해서는
행렬 A의 k번째 index 값들과
행렬 B의 k번째 index 값들의 합입니다.
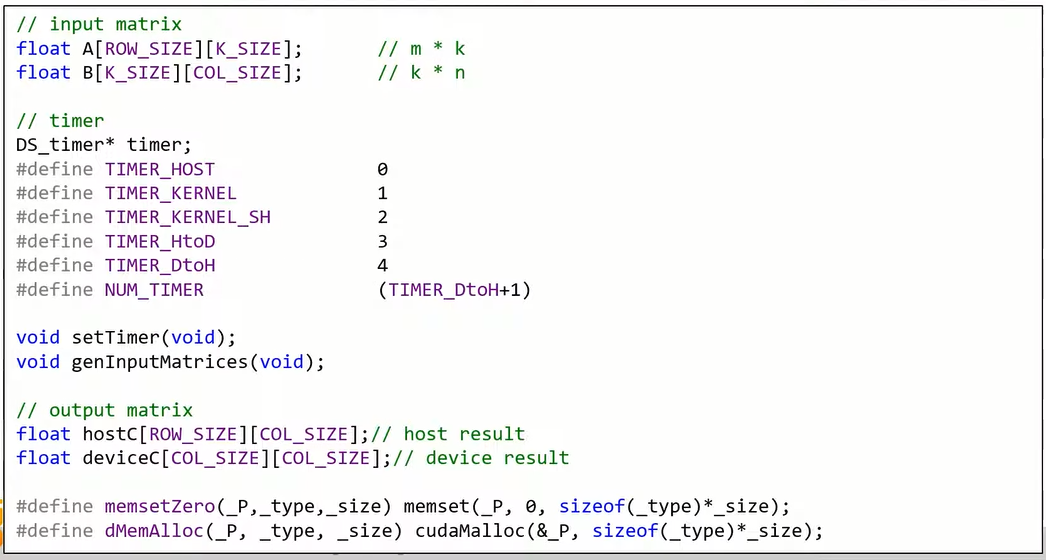
여기서 K_SIZE와 COL_SIZE는 사용자가 주는 값입니다.
 행렬 A
행렬 A
일단 행렬 A의 k번째 index 값을 얻기 위한 식을 먼저 세워줍니다.
 행렬 B
행렬 B
다음으로 행렬 B의 k번째 index를 구해줍니다.
여기서 k값이 0~K_SIZE로 변화함에 따라 원하는 행렬 C의 index값을 얻을 수 있습니다.
행렬 곱을 해보면서 가장 중요한 점은
최종 OutPut으로 나오는 행렬 C를 기준으로
k 와 threadIdx.x 와 threadIdx.y 를 나타내주는 겁니다.
Shared Memory 사용하기!
행렬 A,B,C는 Global Memory에 있는 상태입니다.
행렬 C의 원하는 연산을 하기 위해서는
행렬 A에 접근하는 횟수: row(계산될 A의 행의 개수) * col(계산될 B의 열의 개수) * k
행렬 B에 접근하는 횟수: col(계산될 B의 열의 개수) * row(계산될 A의 행의 개수) * k
최종적으로 row * col * k + col * row * k 가 됩니다.
여기서 행렬 C의 원하는 index 하나를 연산하기 위해서는
행렬 A,B에 각각 k번씩 반복적으로 접근을 하게 됩니다.

k는 임의의 수인 32로
행렬 A의 col 사이즈는 128로
행렬 B의 row 사이즈는 128로
데이터의 크기는 4byte로 정의한 후 진행하겠습니다.
그렇다면
행렬 A의 크기는 4byte * (32 * 128)
행렬 B의 크기는 4byte * (128 * 32)
총 32KB 입니다.
Shared Memory는 보통 64KB이므로 Shared Memory에 넣을 수 있습니다.