HardWare
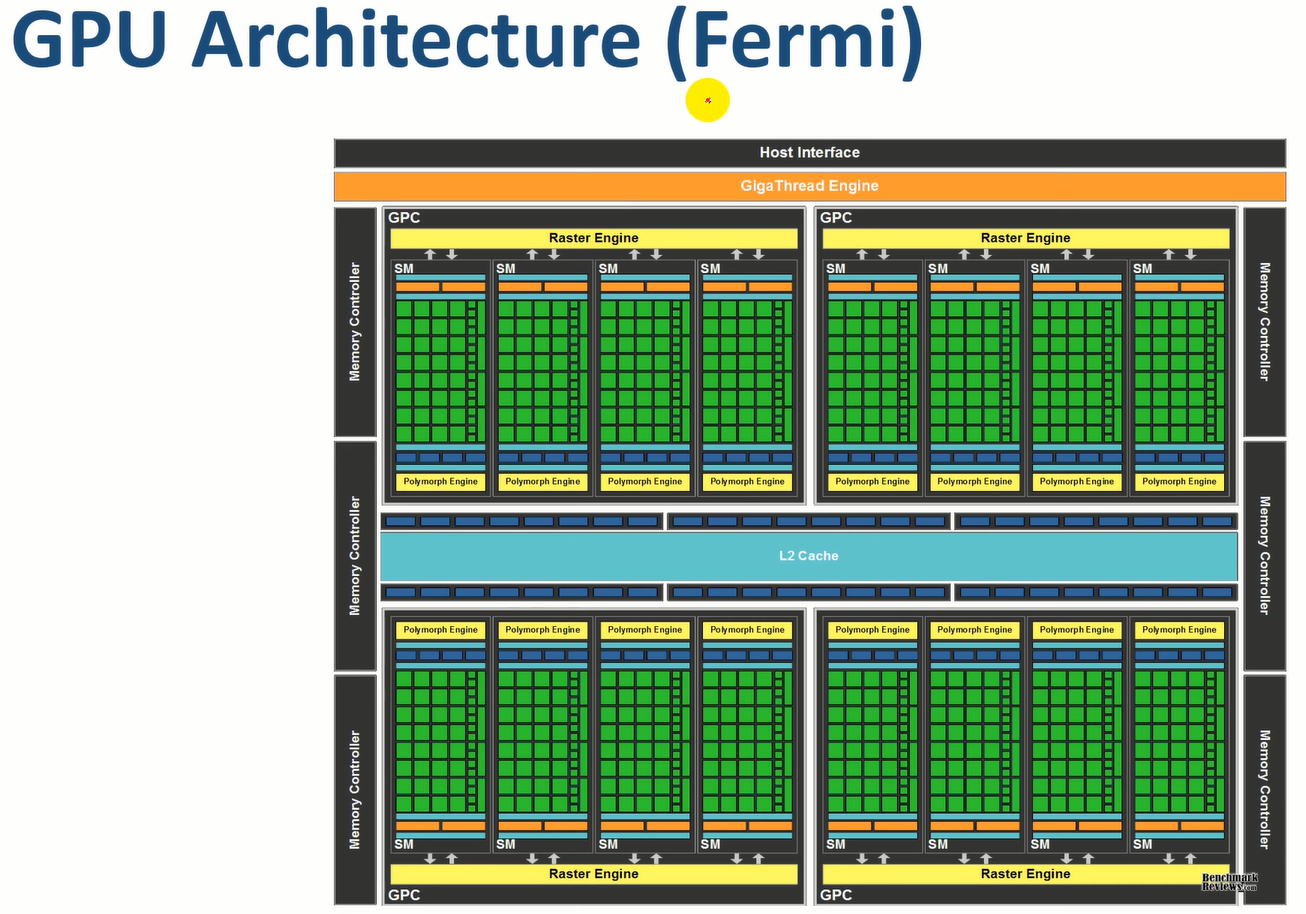

- CUDA core
- Basic processing unit
- 하나의 thread를 처리
- Register, Local memory
- Streaming Multiprocessor (SM)
- block들을 처리
- Shared memory
- Texture/ Cache
Grid, Block

- Grid / Kernel
- Kernel launch 시 생성
- GPU를 사용 하는 단위
- Block
- 각각의 SM에 block들이 배정되어 처리됨
- Active block
- 현재 SM에게 배정된 block
- 개수는 block 당 자원 사용량에 의해 결정됨 - 성능에 영향을 줌
Warp

- Warp
- 각 block은 warp 단위로 분할 됨
- 자신의 execution context를 가짐 - 자기만의 실행 문맥을 가진다.
- Program counters, registers, Etc.
- SM의 register(Register File)를 warp(32개의 thread)가 나누어 가짐
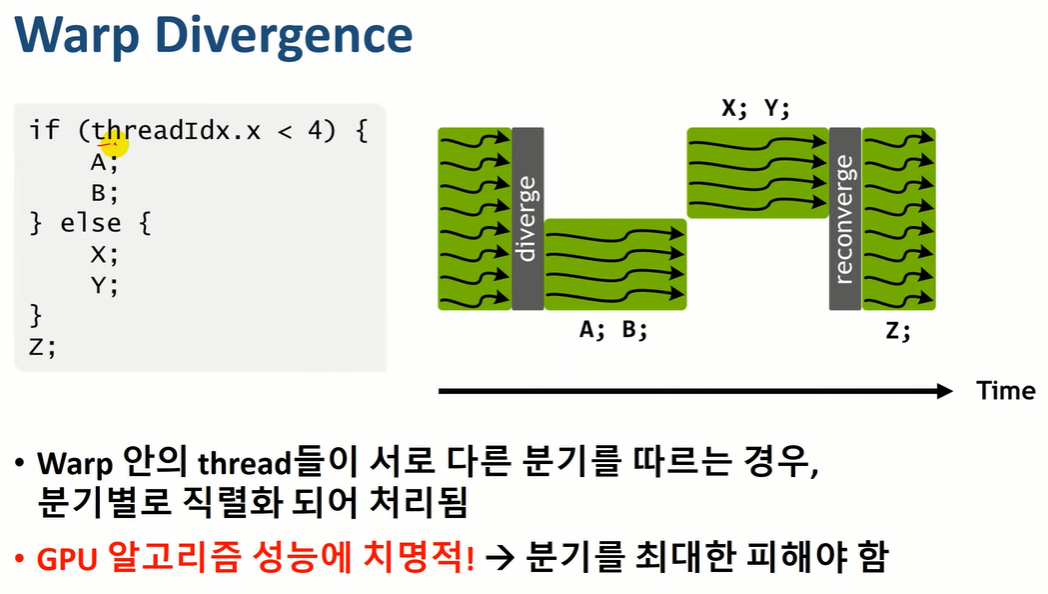
- Warp divergence
- 한 Warp 안의 threads들이 다른 instruction을 진행 하는 경우, 분기 별로 serial 하게 수행됨
- Zero context switching overhead
- 많은 수의 thread를 사용하여, memory access latency를 감출 수 있음
- context가 바뀔때 register에 저장하여 비용이 많이 들지 않는다.
Massive Parallelism for Latency Hiding

출처:
https://www.youtube.com/watch?v=MM04LrNlq2I&list=PLBrGAFAIyf5pp3QNigbh2hRU5EUD0crgI&index=19
'Cuda' 카테고리의 다른 글
| 09_Memory_Active_Warp_CUDA (0) | 2021.09.01 |
|---|---|
| 08_Memory_Architecture_CUDA (0) | 2021.08.30 |
| 06_Where_is_Thread_CUDA (0) | 2021.08.30 |
| 05_How_Kernel_Works_CUDA (0) | 2021.08.30 |
| 04_Vector_Sum_CUDA (0) | 2021.08.27 |