fork() 함수의 리턴값이 각기 다른 것을 이용하여 부모 프로세스와 자식 프로세스가 서로 다른 코드를 실행하도록 분기한다.
#include <unistd.h>
#include <stdio.h>
#include <stdlib.h>
#include <err.h>
static void child()
{
printf("I'm child! my pid is %d.\n", getpid());
exit(EXIT_SUCCESS);
}
static void parent(pid_t pid_c)
{
printf("I'm parent! my pid is %d and the pid of my child is %d.\n", getpid(), pid_c);
exit(EXIT_SUCCESS);
}
int main(void)
{
pid_t ret;
ret = fork();
if (ret == -1)
err(EXIT_FAILURE, "fork() failed");
if (ret == 0) {
// child process came here because fork() returns 0 for child process
child();
} else {
// parent process came here because fork() returns the pid of newly
// created child process (> 1)
parent(ret);
}
// shouldn't reach here
err(EXIT_FAILURE, "shouldn't reach here");
}
// pid_t: 프로세스 번호(pid)를 저장하는 타입(t)이라는 의미
2. execve() 함수
실행 파일을 읽은 다음 프로세스의 메모리 맵에 필요한 정보를 읽어 들인다.
현재 프로세스의 메모리를 새로운 프로세스의 데이터로 덮어쓴다.
새로운 프로세스의 첫 번째 명령부터 실행한다.
즉, 전혀다른 프로그램을 생성하는 경우, 프로세스의 수가 증가하는 것이 아니라, 기존의 프로세스를 별도의 프로세스로 변경하는 방식으로 수행된다.
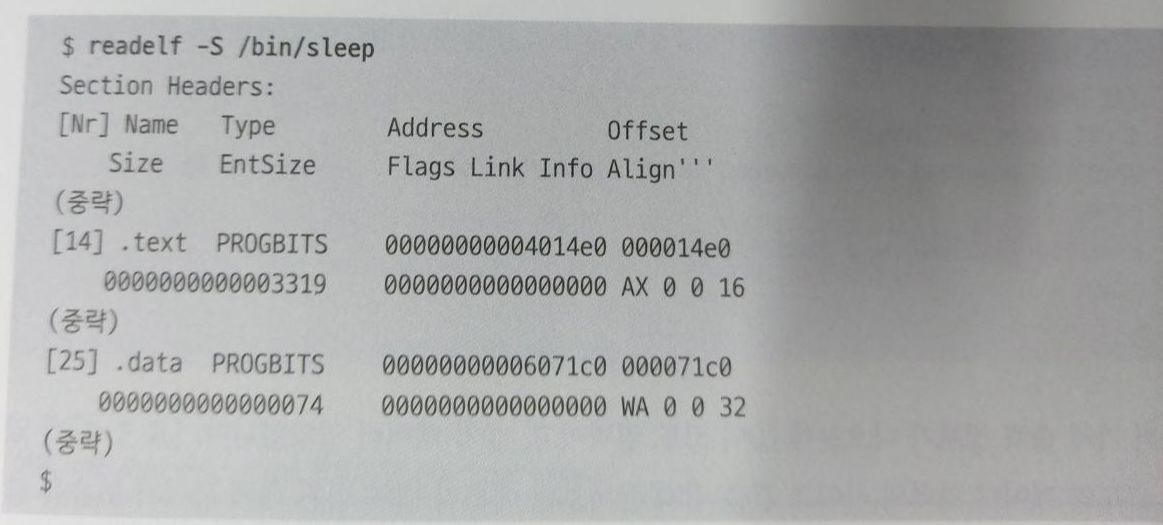
구체적으로 보면 일단 실행 파일을 읽고 프로세스의 메모리 맵에 필요한 정보를 읽어들인다. 실행 파일은 프로세스의 실행 중에 사용하는 코드와 데이터 외에도 아래와 같은 정보가 필요하다.
매핑
-코드를 포함한 데이터 영역의 파일상 오프셋, 사이즈, 메모리맵 시작주소.
-코드 외의 변수 등에서의 데이터 영역에 대한 같은 정보(오프셋, 사이즈, 메모리 맵 시작주소)
-최초로 실행할 명령의 메모리 주소
코드 영역과 데이터 영역의 ‘메모리 맵 시작 주소’가 필요한 이유는 cpu에서 실행되는 기계언어 명령은 고급언어로 쓰인 소스코드와는 다르게 특정 메모리 주소를 지정할 필요가 있기 때문이다.
c = a + b 코드를 기계언어로 바꾸면 다음과 같이 메모리 주소를 직접 조작하는 명령으로 변환(컴파일) 된다.
부모 프로세스는 echo hello 프로그램을 생성한 뒤 자신의 프로세스 ID와 자식의 프로세스 ID를 출력하고 종료한다.
자식 프로세스는 자신의 프로세스 ID를 출력하고 종료한다.
#include <unistd.h>
#include <stdio.h>
#include <stdlib.h>
#include <err.h>
static void child()
{
char *arg[] = {"/bin/echo", "hello", NULL};
printf("I'm child! my pid is %d.\n", getpid());
fflush(stdout);
execve("/bin/echo", arg, NULL);
err(EXIT_FAILURE, "exec() failed");
}
static void parent(pid_t pid_c)
{
printf("I'm parent! my pid is %d and the pid of my child is %d.\n", getpid(), pid_c);
exit(EXIT_SUCCESS);
}
int main(void)
{
pid_t ret;
ret = fork();
if (ret == -1)
err(EXIT_FAILURE, "fork() failed");
if (ret == 0)
{
//child process came here because fork() returns 0 for child process
child();
} else {
//parent process came here because fork() returns the pid of newly
//created child process (>1)
parent(ret);
}
// shouldn't reach here
err(EXIT_FAILURE, "shouldn't reach here");
}