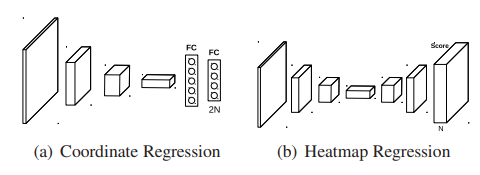
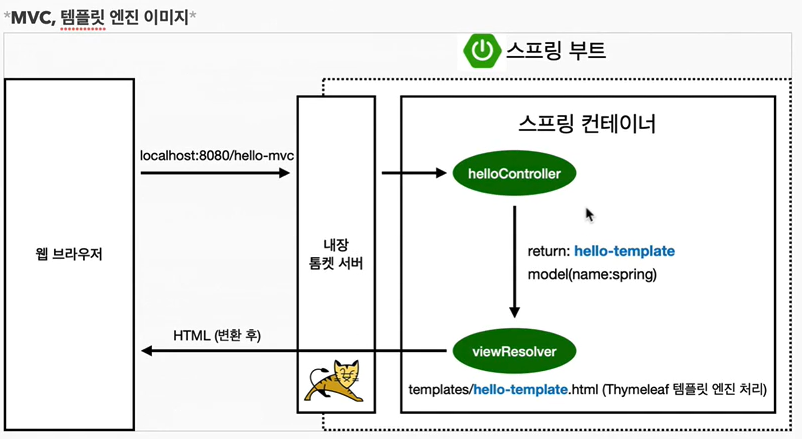
헤더 파일
#pragma once
#ifndef __TENSORFLOW_CLASSIFICATION_H__
#define __TENSORFLOW_CLASSIFICATION_H__
#include <opencv2/opencv.hpp>
#include <iostream>
#include <algorithm>
// 설정 파일
#include "config.h"
// 이미지 처리
#include "img_utils.h"
// dlib
#include "dlib_utils.h"
// tensorflow
#include "tensorflow/c/c_api.h"
static const int64_t face_dim[4] = { 1, IMG_SIZE, IMG_SIZE, 3 };
static std::size_t const face_ndata = IMG_SIZE * IMG_SIZE * 3 * sizeof(float);
static auto const deallocator = [](void*, std::size_t, void*) {};
static std::array<char const*, 1> tags{ "serve" };
class EmoTensorflow
{
private:
static TF_Tensor* make_tensor_input(cv::Mat& face_crop);
static TF_Session* tensorflow_model_load(TF_Buffer** run_options, TF_SessionOptions** session_options, TF_Graph** graph, TF_Status** status);
static int tensorflow_predict(cv::Mat face_tensor, TF_Session** session, TF_Buffer** run_options, TF_Graph** graph, TF_Status** status);
static void delete_variable(TF_Session** session, TF_Buffer** run_options, TF_SessionOptions** session_options, TF_Graph** graph, TF_Status** status);
public:
static int tensorflow_process();
};
#endif
CPP 파일
#include "tensorflow_classification.h"
TF_Tensor* EmoTensorflow::make_tensor_input(cv::Mat& face_crop)
{
//cv::Mat face_crop = cv::imread("./Lenna.png");
cv::resize(face_crop, face_crop, cv::Size(IMG_SIZE, IMG_SIZE), 0, 0, cv::INTER_LINEAR);
cv::cvtColor(face_crop, face_crop, cv::COLOR_BGR2RGB);
face_crop.convertTo(face_crop, CV_32F, 1 / 255.0);
return TF_NewTensor(
TF_FLOAT, face_dim, 4, face_crop.ptr(), face_ndata, deallocator, nullptr
);
}
TF_Session* EmoTensorflow::tensorflow_model_load(TF_Buffer** run_options, TF_SessionOptions** session_options, TF_Graph** graph, TF_Status** status)
{
std::array<char const*, 1> tags{ "serve" };
TF_Session* model = TF_LoadSessionFromSavedModel(
*session_options, *run_options, "./model/mobilenetv1_64_padding",
tags.data(), tags.size(), *graph, nullptr, *status);
// Check Model
if (TF_GetCode(*status) != TF_OK) {
std::cout << TF_Message(*status) << '\n';
}
// Load Model
return model;
}
int EmoTensorflow::tensorflow_predict(cv::Mat face_crop, TF_Session** session, TF_Buffer** run_options, TF_Graph** graph, TF_Status** status)
{
TF_Tensor* face_tensor = EmoTensorflow::make_tensor_input(face_crop);
TF_Operation* input_op = TF_GraphOperationByName(*graph, "serving_default_input_1");
if (input_op == nullptr) {
std::cout << "Failed to find graph operation\n" << std::endl;
}
TF_Operation* output_op = TF_GraphOperationByName(*graph, "StatefulPartitionedCall");
if (output_op == nullptr) {
std::cout << "Failed to find graph operation\n" << std::endl;
}
std::array<TF_Output, 1> input_ops = { TF_Output{ input_op, 0} };
std::array<TF_Output, 1> output_ops = { TF_Output{ output_op, 0} };
std::array<TF_Tensor*, 1> input_values{ face_tensor };
std::array<TF_Tensor*, 7> output_values{};
TF_SessionRun(*session,
*run_options,
input_ops.data(), input_values.data(), input_ops.size(),
output_ops.data(), output_values.data(), output_ops.size(),
nullptr, 0, nullptr, *status
);
auto* output_tensor = static_cast<std::array<float, 7> *>(TF_TensorData(output_values[0]));
std::vector<std::array<float, 7>> outputs{ output_tensor, output_tensor + 1 };
float max_value = *max_element(outputs[0].begin(), outputs[0].end());
return (std::find(outputs[0].begin(), outputs[0].end(), max_value) - outputs[0].begin());
}
void EmoTensorflow::delete_variable(TF_Session** session, TF_Buffer** run_options, TF_SessionOptions** session_options, TF_Graph** graph, TF_Status** status)
{
TF_DeleteBuffer(*run_options);
TF_DeleteSessionOptions(*session_options);
TF_DeleteSession(*session, *status);
TF_DeleteGraph(*graph);
TF_DeleteStatus(*status);
}
int EmoTensorflow::tensorflow_process()
{
Img_preprocessing img_tools = Img_preprocessing();
face_detect face_detector = face_detect();
mmod_net mmod_model;
dlib::frontal_face_detector fog_model;
// Create variables for tensorflow, 모델 변수 선언
TF_Buffer* run_options = TF_NewBufferFromString("", 0);
TF_SessionOptions* session_options = TF_NewSessionOptions();
TF_Graph* graph = TF_NewGraph();
TF_Status* status = TF_NewStatus();
// Load Model
TF_Session* session = EmoTensorflow::tensorflow_model_load(&run_options, &session_options, &graph, &status);
// Read Video
cv::VideoCapture cap;
// Setting camera
img_tools.set_camera(cap);
// Setting face_detector
if (FACE_METHOD == 0) // dlib
{
if (DLIB_STYLE == "CNN")
{
face_detector.load_mmod(mmod_model);
}
else
{
face_detector.load_hog(fog_model);
}
}
// Start Video
cv::Mat frame;
cv::Mat face_img;
int output = -1;
std::vector<int> face_positions;
while (true)
{
cap >> frame;
double start_time = clock();
face_detector.detect_face(mmod_model, fog_model, frame, face_positions);
if (face_positions.size() != 0)
{
for (int idx = 0; idx < face_positions.size() - 3; idx += 4)
{
cv::Rect face_rect(cv::Point(face_positions[idx], face_positions[idx + 1]), cv::Point(face_positions[idx + 2], face_positions[idx + 3]));
frame(face_rect).copyTo(face_img);
cv::cvtColor(face_img, face_img, cv::COLOR_BGR2RGB);
if (PADDING) { img_tools.add_padding(face_img); }
img_tools.resize_img(face_img);
output = EmoTensorflow::tensorflow_predict(face_img, &session, &run_options, &graph, &status);
img_tools.draw_bbox(frame, face_positions[idx], face_positions[idx + 1], face_positions[idx + 2], face_positions[idx + 3], output);
img_tools.put_text(frame, face_positions[idx], face_positions[idx + 1], face_positions[idx + 2], face_positions[idx + 3], output);
output = -1;
}
}
double terminate_time = clock();
std::cout << "start_time : " << start_time << std::endl;
std::cout << "terminate_time : " << terminate_time << std::endl;
std::cout << (terminate_time - start_time) / CLOCKS_PER_SEC << std::endl;
if (SHOW_FPS)
{
img_tools.put_fps(frame, (1.0 / ((terminate_time - start_time) / CLOCKS_PER_SEC)));
}
face_positions.clear();
cv::imshow("test", frame);
if (cv::waitKey(1) == 27) { break; }
}
EmoTensorflow::delete_variable(&session, &run_options, &session_options, &graph, &status);
return 0;
}