TensorRT 공식 가이드 문서를 보며 작성하였습니다.
잘못된 점이 있다면 댓글 부탁드립니다.
TensorRT는 C++, Python API를 지원하지만
7.x.x 이하 버전에서 Python API는 Linux 환경만 지원하는 걸로 알고 있습니다. (불명확)
이 글은 C++ API 를 위주로 작성하겠습니다.
공식 가이드 문서상 TensorRT는 2단계로 작동합니다.
첫번째, Builder Phase : TensorRT에 Model Definition을 제공해주고 TensorRT가 GPU에 맞게 최적화를 진행합니다.
두번째, Runtime Phase : 최적화된 Model을 사용하면 됩니다!
그런데 말만 2단계지 더 많은것 같다...
1. Builder Phase
TensorRT에서의 Builder는 Model을 최적화 해주는 기능을 가지고 있으며,
Engine이라는 산출물을 Output으로 가집니다.
Build 내부 단계는 아래의 3단계입니다.
- Create network definition : network를 정의해줍니다.
- Specify a configuration for the builder : builder를 위한 환경을 명시해줍니다.
- Call the builder to create the engine : engine을 만들기 위해 builder를 사용합니다.
2. Runtime Phase
Runtim Phase는 아래의 2단계로 나뉘어 집니다.
- Deserialize a plan to create an engine : 생성된 엔진을 가져와서 사용합니다.
- Create an execution context from the engine : 자세히는 모르겠지만 가져온 엔진을 컨트롤...? 하는것 같다.
Builder Phase CODE
class Logger : public ILogger
{
void log(Severity severity, const char* msg) override
{
// suppress info-level messages
if (severity <= Severity::kWARNING)
std::cout << msg << std::endl;
}
} logger;builder를 만들기 위해서는 ILogger를 먼저 선언해줍니다.
IBuilder* builder = createInferBuilder(logger);logger를 이용해 builder를 선언해줍니다.
IBuilderConfig* config = builder->createBuilderConfig();
config->setMaxWorkspaceSize(1U << 20);그리고 builder의 config를 선언해줍니다.
여기서 config에는 많은 설정환경이 있고
그중에 setMaxWorkspaceSize는 Layer를 구축하는데 있어서 최대 Memory Size를 설정하는 옵션입니다.
uint32_t flag = 1U <<static_cast<uint32_t>
(NetworkDefinitionCreationFlag::kEXPLICIT_BATCH)
INetworkDefinition* network = builder->createNetworkV2(flag);그 후 builder의 network를 선언해줍니다.
이제 network에 layer들을 정의 시켜줍니다.
#include “NvOnnxParser.h”
Using namespace nvonnxparser;
IParser* parser = createParser(*network, logger);
parser->parseFromFile(modelFile, ILogger::Severity::kWARNING);
for (int32_t i = 0; i < parser.getNbErrors(); ++i)
{
std::cout << parser->getError(i)->desc() << std::endl;
}ONNX를 이용한다면 위와 같은 코드를 이용하면 됩니다.
직접 tensorRT로 layer를 구축하는 것은 다음 게시물에 게시하겠습니다.
IHostMemory* serializedModel = builder->buildSerializedNetwork(*network, *config);위에서 정의한 network와 config를 이용하여 engine을 build 및 serialize 해줍니다.
IHostMemory는 그냥 간단하게 handle이라고 생각하는게 맘편할거 같고...
여기서
1. builder->buildSerializeNetwork(*network, *config)
2. builder->buildEngineWithConfig(*network, *config)
두 종류의 함수를 사용할 수 있는데
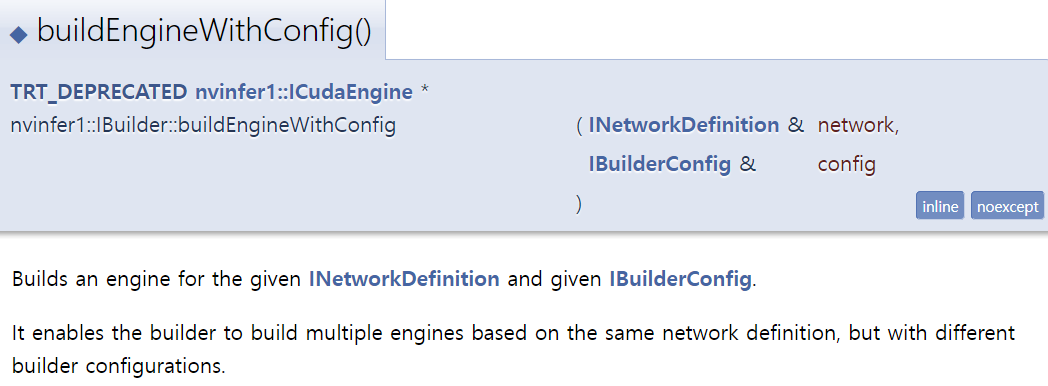
2번 함수는 serialize를 제외하고 build만 적용하여
Output으로 ICudaEngine* 형식의 engine 을 반환하게 되고,
이 engine 을 저장하기 위해서는
IHostMemory* modelStream = engine->serialize();
serialize 한 후 저장을 진행해줍니다.
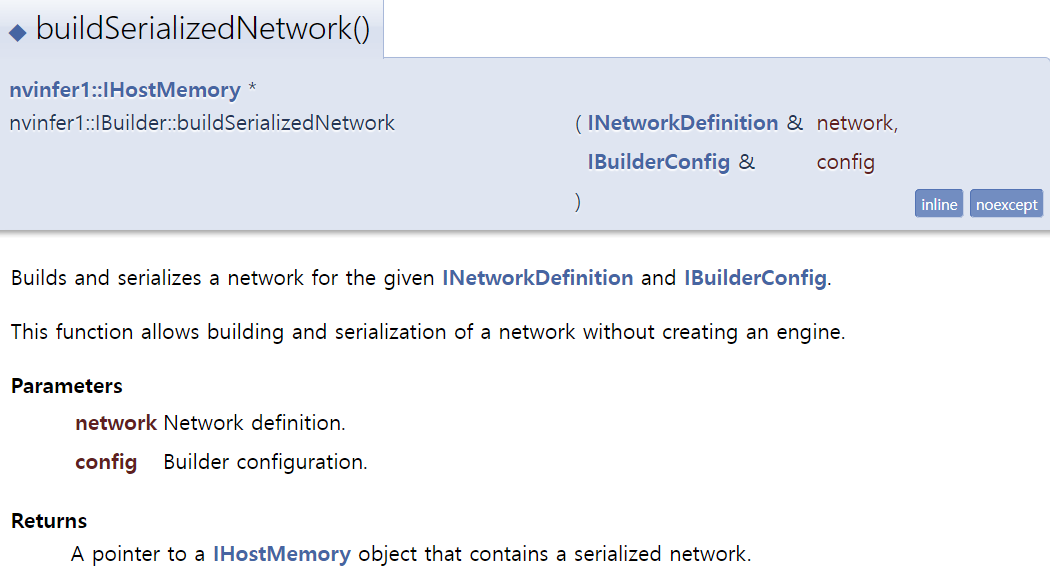
1번 함수는 엔진 생성 없이 build 및 serialize 해줍니다.
std::ofstream p("engine_name.engine", std::ios::binary);
if (!p) {
std::cerr << "could not open plan output file" << std::endl;
return -1;
}
p.write(reinterpret_cast<const char*>(serializedModel->data()), serializedModel->size());위에서 생성된 serializedModel을 저장을 해줍니다.
build하는 과정에서 시간이 걸리므로 나중에 재사용하기 위해서는 engine 파일을 저장해두는 것이 좋습니다.
delete parser;
delete network;
delete config;
delete builder;
delete serializedModelengine을 저장해줬으면 위에 선언했던 변수들을 delete 해줍니다.
Runtime Phase CODE
Build Phase 에서 ONNX를 통해 만들어준 engine을 사용해보겠습니다.
std::ifstream engineFile( fileName, std::ios::binary );
if ( !engineFile ) {
std::cout << "can not open file : " << fileName << std::endl;
return false;
}먼저 저장된 engine 파일을 불러옵니다.
engineFile.seekg( 0, engineFile.end );
auto fsize = engineFile.tellg();
engineFile.seekg( 0, engineFile.beg );불러온 engine 파일의 사이즈를 계산해주고 다시 파일의 시작부분으로 옮겨줍니다.
※ 참고사항
engineFile.seekg(A, B) → engineFile에서 B의 위치에서 A만큼의 위치
ex)
- engineFile.seekg(0, engineFile.end) → engineFile의 끝에서 0만큼 이동한 위치
- engineFile.seekg(0, engineFile.beg) → engineFile의 처음에서 0만큼 이동한 위치
std::vector<char> engineData( fsize );
engineFile.read( engineData.data(), fsize );그 후 engineFile 내부 데이터를 가져옵니다.
nvinfer1::IRuntime *runtime = nvinfer1::createInferRuntime( gLogger.getTRTLogger() );
engine_ = runtime->deserializeCudaEngine( engineData, fsize, nullptr );마지막으로 engine을 deserialize하기 위해 IRuntime을 선언해주고 deserializeCudaEngine을 사용하면 됩니다.
Inference CODE
const char* INPUT_BLOB_NAME = "data";
const char* OUTPUT_BLOB_NAME = "prob";
void* buffers[2];
IExecutionContext *context = engine->createExecutionContext();
const int inputIndex = engine.getBindingIndex(INPUT_BLOB_NAME);
const int outputIndex = engine.getBindingIndex(OUTPUT_BLOB_NAME);
// Create GPU buffers on device
// GPU에 공간 할당을 해줍니다.
CHECK(cudaMalloc(&buffers[inputIndex], batchSize * 3 * INPUT_H * INPUT_W * sizeof(float)));
CHECK(cudaMalloc(&buffers[outputIndex], batchSize * OUTPUT_SIZE * sizeof(float)));
// Create stream
cudaStream_t stream;
CHECK(cudaStreamCreate(&stream));
// DMA input batch data to device, infer on the batch asynchronously, and DMA output back to host
// GPU의 할당된 공간에 data를 복사하고 실행해줍니다.
CHECK(cudaMemcpyAsync(buffers[inputIndex], input, batchSize * 3 * INPUT_H * INPUT_W * sizeof(float), cudaMemcpyHostToDevice, stream));
context.enqueue(batchSize, buffers, stream, nullptr);
CHECK(cudaMemcpyAsync(output, buffers[outputIndex], batchSize * OUTPUT_SIZE * sizeof(float), cudaMemcpyDeviceToHost, stream));
cudaStreamSynchronize(stream);
// Release stream and buffers
cudaStreamDestroy(stream);
CHECK(cudaFree(buffers[inputIndex]));
CHECK(cudaFree(buffers[outputIndex]));
※ TensorRT 공식 가이드 문서 :
https://docs.nvidia.com/deeplearning/tensorrt/developer-guide/index.html#overview
https://docs.nvidia.com/deeplearning/tensorrt/developer-guide/index.html#build-phase-c
※ 참고 자료:
https://seobway.tistory.com/entry/TensorRT-1-Build-tensorrt-engine-tensorRT-723?category=850806
※ 참고자료 : ONNX 변환 및 사용 - 갓꾸준희님
https://eehoeskrap.tistory.com/414
※ 참고 github - tensorRT 예제 코드 정리 잘되어 있음!
https://github.com/wang-xinyu/tensorrtx
'Deep Learning > TensorRT' 카테고리의 다른 글
| 06. TensorRT Resnet18 (0) | 2023.03.21 |
|---|---|
| 05. TensorRT VGG (0) | 2023.03.11 |
| 04. TensorRT Custom Layer 만들기 (0) | 2022.02.14 |
| 01. TensorRT 설치 및 다운로드 (0) | 2022.02.11 |