Weights 추출하기
import struct
import torch
from torchvision import models
from torchsummary import summary
if __name__ == '__main__':
resnet18 = models.resnet18(pretrained=True)
resnet18.to('cuda:0')
resnet18.eval()
summary(resnet18, (3, 224, 224))
input = torch.ones(1, 3, 224, 224).to('cuda:0')
out = resnet18(input)
# Weights Extraction
f = open('resnet18.wts', 'w')
f.write('{}\n'.format(len(resnet18.state_dict().keys())))
for k, v in resnet18.state_dict().items():
print('key: {} value: {}'.format(k, v.shape))
vr = v.reshape(-1).cpu().numpy()
f.write('{} {}'.format(k, len(vr)))
for vv in vr:
f.write(' ')
f.write(struct.pack(">f", float(vv)).hex())
f.write('\n')
※ Key, Value 정보
key: conv1.weight value: torch.Size([64, 3, 7, 7])
key: bn1.weight value: torch.Size([64])
key: bn1.bias value: torch.Size([64])
key: bn1.running_mean value: torch.Size([64])
key: bn1.running_var value: torch.Size([64])
key: bn1.num_batches_tracked value: torch.Size([])
key: layer1.0.conv1.weight value: torch.Size([64, 64, 3, 3])
key: layer1.0.bn1.weight value: torch.Size([64])
key: layer1.0.bn1.bias value: torch.Size([64])
key: layer1.0.bn1.running_mean value: torch.Size([64])
key: layer1.0.bn1.running_var value: torch.Size([64])
key: layer1.0.bn1.num_batches_tracked value: torch.Size([])
key: layer1.0.conv2.weight value: torch.Size([64, 64, 3, 3])
key: layer1.0.bn2.weight value: torch.Size([64])
key: layer1.0.bn2.bias value: torch.Size([64])
key: layer1.0.bn2.running_mean value: torch.Size([64])
key: layer1.0.bn2.running_var value: torch.Size([64])
key: layer1.0.bn2.num_batches_tracked value: torch.Size([])
key: layer1.1.conv1.weight value: torch.Size([64, 64, 3, 3])
key: layer1.1.bn1.weight value: torch.Size([64])
key: layer1.1.bn1.bias value: torch.Size([64])
key: layer1.1.bn1.running_mean value: torch.Size([64])
key: layer1.1.bn1.running_var value: torch.Size([64])
key: layer1.1.bn1.num_batches_tracked value: torch.Size([])
key: layer1.1.conv2.weight value: torch.Size([64, 64, 3, 3])
key: layer1.1.bn2.weight value: torch.Size([64])
key: layer1.1.bn2.bias value: torch.Size([64])
key: layer1.1.bn2.running_mean value: torch.Size([64])
key: layer1.1.bn2.running_var value: torch.Size([64])
key: layer1.1.bn2.num_batches_tracked value: torch.Size([])
key: layer2.0.conv1.weight value: torch.Size([128, 64, 3, 3])
key: layer2.0.bn1.weight value: torch.Size([128])
key: layer2.0.bn1.bias value: torch.Size([128])
key: layer2.0.bn1.running_mean value: torch.Size([128])
key: layer2.0.bn1.running_var value: torch.Size([128])
key: layer2.0.bn1.num_batches_tracked value: torch.Size([])
key: layer2.0.conv2.weight value: torch.Size([128, 128, 3, 3])
key: layer2.0.bn2.weight value: torch.Size([128])
key: layer2.0.bn2.bias value: torch.Size([128])
key: layer2.0.bn2.running_mean value: torch.Size([128])
key: layer2.0.bn2.running_var value: torch.Size([128])
key: layer2.0.bn2.num_batches_tracked value: torch.Size([])
key: layer2.0.downsample.0.weight value: torch.Size([128, 64, 1, 1])
key: layer2.0.downsample.1.weight value: torch.Size([128])
key: layer2.0.downsample.1.bias value: torch.Size([128])
key: layer2.0.downsample.1.running_mean value: torch.Size([128])
key: layer2.0.downsample.1.running_var value: torch.Size([128])
key: layer2.0.downsample.1.num_batches_tracked value: torch.Size([])
key: layer2.1.conv1.weight value: torch.Size([128, 128, 3, 3])
key: layer2.1.bn1.weight value: torch.Size([128])
key: layer2.1.bn1.bias value: torch.Size([128])
key: layer2.1.bn1.running_mean value: torch.Size([128])
key: layer2.1.bn1.running_var value: torch.Size([128])
key: layer2.1.bn1.num_batches_tracked value: torch.Size([])
key: layer2.1.conv2.weight value: torch.Size([128, 128, 3, 3])
key: layer2.1.bn2.weight value: torch.Size([128])
key: layer2.1.bn2.bias value: torch.Size([128])
key: layer2.1.bn2.running_mean value: torch.Size([128])
key: layer2.1.bn2.running_var value: torch.Size([128])
key: layer2.1.bn2.num_batches_tracked value: torch.Size([])
key: layer3.0.conv1.weight value: torch.Size([256, 128, 3, 3])
key: layer3.0.bn1.weight value: torch.Size([256])
key: layer3.0.bn1.bias value: torch.Size([256])
key: layer3.0.bn1.running_mean value: torch.Size([256])
key: layer3.0.bn1.running_var value: torch.Size([256])
key: layer3.0.bn1.num_batches_tracked value: torch.Size([])
key: layer3.0.conv2.weight value: torch.Size([256, 256, 3, 3])
key: layer3.0.bn2.weight value: torch.Size([256])
key: layer3.0.bn2.bias value: torch.Size([256])
key: layer3.0.bn2.running_mean value: torch.Size([256])
key: layer3.0.bn2.running_var value: torch.Size([256])
key: layer3.0.bn2.num_batches_tracked value: torch.Size([])
key: layer3.0.downsample.0.weight value: torch.Size([256, 128, 1, 1])
key: layer3.0.downsample.1.weight value: torch.Size([256])
key: layer3.0.downsample.1.bias value: torch.Size([256])
key: layer3.0.downsample.1.running_mean value: torch.Size([256])
key: layer3.0.downsample.1.running_var value: torch.Size([256])
key: layer3.0.downsample.1.num_batches_tracked value: torch.Size([])
key: layer3.1.conv1.weight value: torch.Size([256, 256, 3, 3])
key: layer3.1.bn1.weight value: torch.Size([256])
key: layer3.1.bn1.bias value: torch.Size([256])
key: layer3.1.bn1.running_mean value: torch.Size([256])
key: layer3.1.bn1.running_var value: torch.Size([256])
key: layer3.1.bn1.num_batches_tracked value: torch.Size([])
key: layer3.1.conv2.weight value: torch.Size([256, 256, 3, 3])
key: layer3.1.bn2.weight value: torch.Size([256])
key: layer3.1.bn2.bias value: torch.Size([256])
key: layer3.1.bn2.running_mean value: torch.Size([256])
key: layer3.1.bn2.running_var value: torch.Size([256])
key: layer3.1.bn2.num_batches_tracked value: torch.Size([])
key: layer4.0.conv1.weight value: torch.Size([512, 256, 3, 3])
key: layer4.0.bn1.weight value: torch.Size([512])
key: layer4.0.bn1.bias value: torch.Size([512])
key: layer4.0.bn1.running_mean value: torch.Size([512])
key: layer4.0.bn1.running_var value: torch.Size([512])
key: layer4.0.bn1.num_batches_tracked value: torch.Size([])
key: layer4.0.conv2.weight value: torch.Size([512, 512, 3, 3])
key: layer4.0.bn2.weight value: torch.Size([512])
key: layer4.0.bn2.bias value: torch.Size([512])
key: layer4.0.bn2.running_mean value: torch.Size([512])
key: layer4.0.bn2.running_var value: torch.Size([512])
key: layer4.0.bn2.num_batches_tracked value: torch.Size([])
key: layer4.0.downsample.0.weight value: torch.Size([512, 256, 1, 1])
key: layer4.0.downsample.1.weight value: torch.Size([512])
key: layer4.0.downsample.1.bias value: torch.Size([512])
key: layer4.0.downsample.1.running_mean value: torch.Size([512])
key: layer4.0.downsample.1.running_var value: torch.Size([512])
key: layer4.0.downsample.1.num_batches_tracked value: torch.Size([])
key: layer4.1.conv1.weight value: torch.Size([512, 512, 3, 3])
key: layer4.1.bn1.weight value: torch.Size([512])
key: layer4.1.bn1.bias value: torch.Size([512])
key: layer4.1.bn1.running_mean value: torch.Size([512])
key: layer4.1.bn1.running_var value: torch.Size([512])
key: layer4.1.bn1.num_batches_tracked value: torch.Size([])
key: layer4.1.conv2.weight value: torch.Size([512, 512, 3, 3])
key: layer4.1.bn2.weight value: torch.Size([512])
key: layer4.1.bn2.bias value: torch.Size([512])
key: layer4.1.bn2.running_mean value: torch.Size([512])
key: layer4.1.bn2.running_var value: torch.Size([512])
key: layer4.1.bn2.num_batches_tracked value: torch.Size([])
key: fc.weight value: torch.Size([1000, 512])
key: fc.bias value: torch.Size([1000])
TensorRT 사용하기
ResNet에는 Basic Block이라고 여러 Layer들로 구성되어 있는걸 사용합니다.
※ Basic Block TensorRT
IActivationLayer* BasicBlock(INetworkDefinition* network, std::map<std::string, Weights> weightMap, ITensor& input, int inc, int outc, int stride, std::string lname)
{
Weights emptywts{ DataType::kFLOAT, nullptr, 0 };
IConvolutionLayer* cv01 = network->addConvolutionNd(input, outc, DimsHW{ 3, 3 }, weightMap[lname + ".conv1.weight"], emptywts);
assert(cv01);
cv01->setStrideNd(DimsHW{ stride, stride });
cv01->setPaddingNd(DimsHW{ 1, 1 });
IScaleLayer* bn1 = addBatchNorm2d(network, weightMap, *cv01->getOutput(0), lname + ".bn1", 1e-5);
IActivationLayer* relu1 = network->addActivation(*bn1->getOutput(0), ActivationType::kRELU);
assert(relu1);
IConvolutionLayer* cv02 = network->addConvolutionNd(*relu1->getOutput(0), outc, DimsHW{ 3, 3 }, weightMap[lname + ".conv2.weight"], emptywts);
cv02->setPaddingNd(DimsHW{ 1, 1 });
assert(cv02);
IScaleLayer* bn2 = addBatchNorm2d(network, weightMap, *cv02->getOutput(0), lname + ".bn2", 1e-5);
// 잔차 학습
IElementWiseLayer* sum;
if (inc == outc)
{
sum = network->addElementWise(input, *bn2->getOutput(0), ElementWiseOperation::kSUM);
}
else
{
IConvolutionLayer* cv03 = network->addConvolutionNd(*bn2->getOutput(0), outc, DimsHW(1, 1), weightMap[lname + ".downsample.0.weight", emptywts);
cv03->setStrideNd(DimsHW{ stride, stride });
IScaleLayer* bn3 = addBatchNorm2d(network, weightMap, *cv03->getOutput(0), lname + ".downsample.1", 1e-5);
sum = network->addElementWise(*bn2->getOutput(0), *bn3->getOutput(0), ElementWiseOperation::kSUB);
}
IActivationLayer* relu2 = network->addActivation(*sum->getOutput(0), ActivationType::kRELU);
assert(relu2);
return relu2;
}이렇게 반복적으로 사용하는 Layer들의 집합을 구성할때 주의해야 할 것이 있는데,
바로 stride와 padding 같은 Parameter 값들 입니다.
각 Layer 별로 규칙성 있게 사용한다면 그것에 맞게 구성해줘야 합니다.
ResNet의 BasicBlock의 경우
DownSampling이 진행되는 Basic Block이 있기 때문에 input channel과 output channel 값을 비교하여 구성해주어야 합니다.
※ Basic Block (layer1)
Sequential(
(0): BasicBlock(
(conv1): Conv2d(64, 64, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn1): BatchNorm2d(64, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(relu): ReLU(inplace=True)
(conv2): Conv2d(64, 64, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn2): BatchNorm2d(64, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
)
(1): BasicBlock(
(conv1): Conv2d(64, 64, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn1): BatchNorm2d(64, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(relu): ReLU(inplace=True)
(conv2): Conv2d(64, 64, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn2): BatchNorm2d(64, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
)
)
또 하나 중요한 점은 Pytorch 코드를 돌리면서 위와 같이 Layer들의 정보를 볼 수 있습니다.
하지만 잔차학습이 어디서 이루어 지는지는 파악할 수 없습니다.
그래서 직접 Data Flow를 따라 들어가며 구성되어 있는 Layer들을 파악해야 합니다.
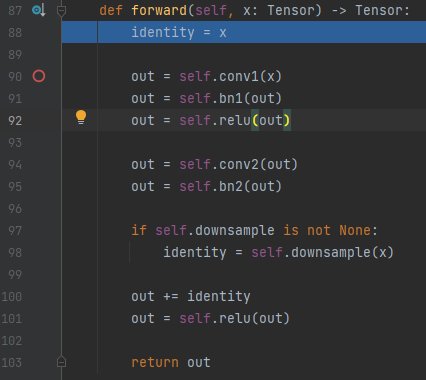
위처럼 연산이 이루어집니다.
즉, Layer 요약본만 보고 진행하면 안되고 하나하나 다 들어가서 봐야 합니다.
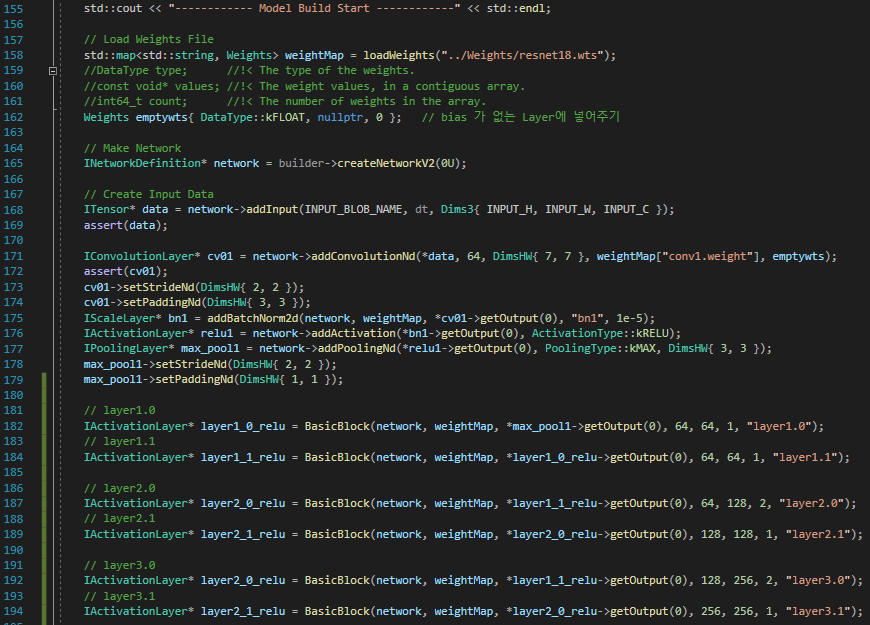
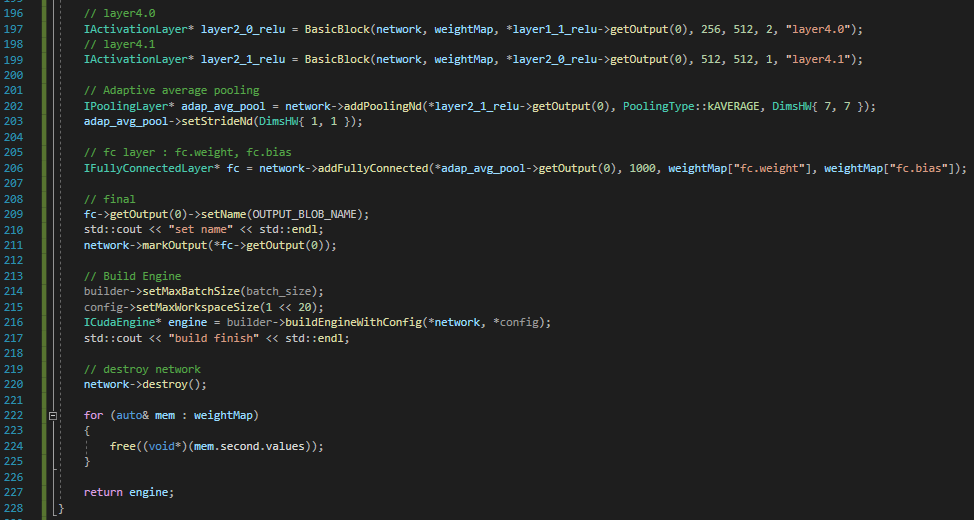
위 사진 2장은 Layer를 보며 직접 쌓아 올렸습니다.
진행하면서 막히는 부분은 github를 참고하며 진행했습니다.
TensorRT에서 BatchNorm을 사용하려면 직접 작성해주어야 합니다.
공식은 아래 사진을 사용했습니다.
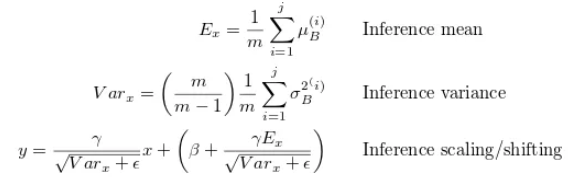

이제 모델 Layer를 다 쌓아 올렸으면 Engine을 생성해주어야 합니다.
※ Engine 생성
// 3. engine 생성
if (make_engine)
{
std::cout << "------------ Create " << engineFileName << " Engine ------------" << std::endl;
// Make Builder
IBuilder* builder = createInferBuilder(gLogger);
// Make Config
IBuilderConfig* config = builder->createBuilderConfig();
// Create Engine
ICudaEngine* engine = createEngine(batch_size, builder, config, DataType::kFLOAT, engine_file_path);
assert(engine != nullptr);
IHostMemory* modelStream{ nullptr };
*(&modelStream) = engine->serialize();
// check engine file
std::ofstream p("resnet18.engine", std::ios::binary);
if (!p)
{
std::cerr << "could not open plan output file" << std::endl;
return -1;
}
p.write(reinterpret_cast<const char*>(modelStream->data()), modelStream->size());
// Destroy builder, config
modelStream->destroy();
builder->destroy();
config->destroy();
}
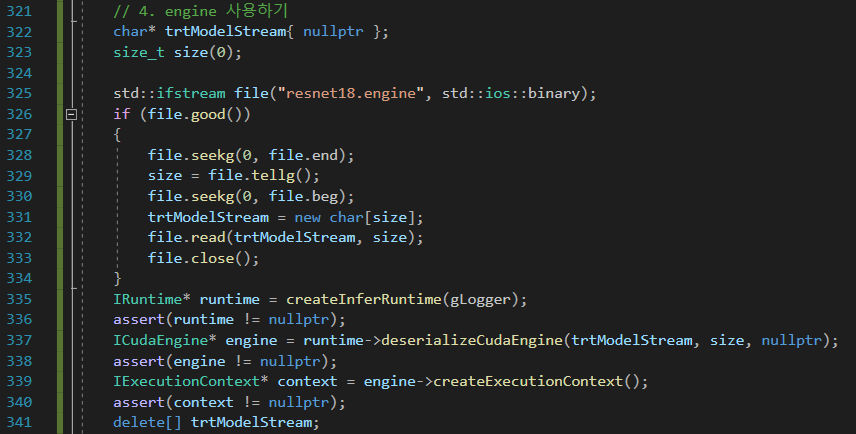
※ Call Engine
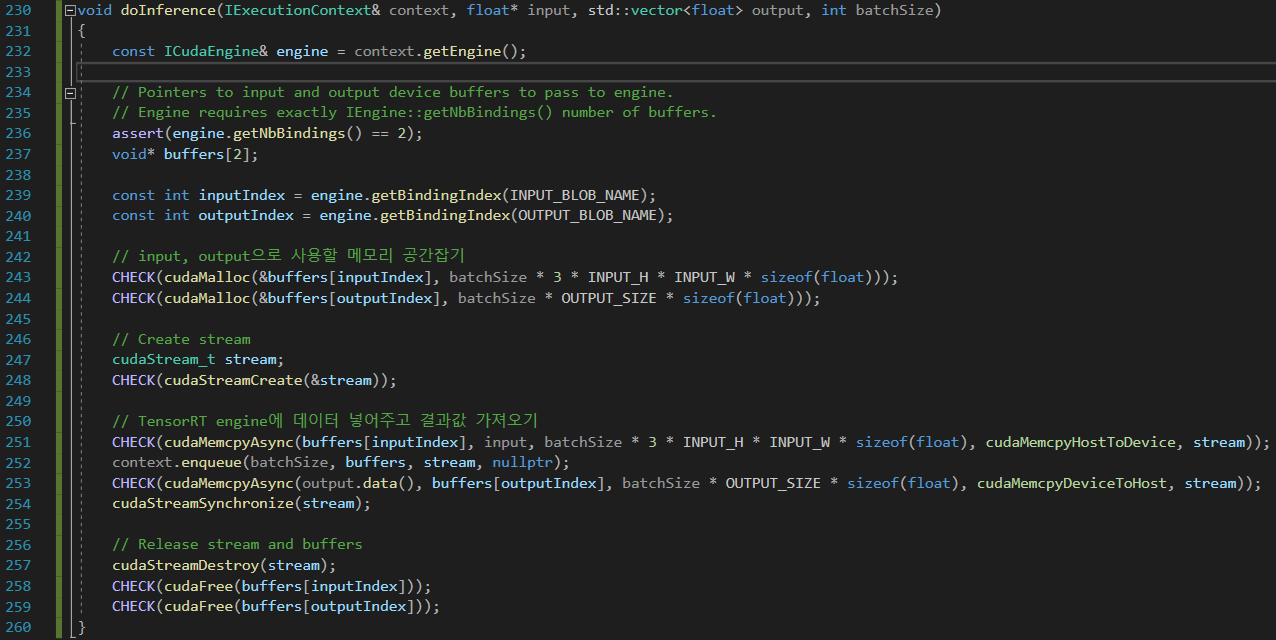
※ Inference
※ 출처
'Deep Learning > TensorRT' 카테고리의 다른 글
| 05. TensorRT VGG (0) | 2023.03.11 |
|---|---|
| 04. TensorRT Custom Layer 만들기 (0) | 2022.02.14 |
| 02. TensorRT 다루기 (0) | 2022.02.11 |
| 01. TensorRT 설치 및 다운로드 (0) | 2022.02.11 |